MSX 룬워스 한글 출력을 위한 폰트 확장
by

SeHwa
지난 번 포스트에서는 이미 공개된 한국어화에 살짝 보완을 해봤을 뿐이지만, 이번에는 바닥부터 새로 한국어화를 위한 분석 작업을 하기로 했다. 순전히 기술적 흥미를 위해 하는 것이기 때문에, 한국어화할 게임 선택 기준은 보통의 일반적인 방식으로 한국어화를 하려면 상대적으로 까다로운 작품으로 선택했다. 우선 먼저 MSX 에서 한국어화에 기술적인 문제가 있을 것으로 추정되는 게임을 찾아보기로 했고, 그렇게 해서 선택한 게임이 룬워스(Rune Worth) 이다.
Background
게임에 대한 간략한 설명은 아래와 같다.

| 출시 연도 | 1989년 |
| 개발사 | T&E Soft |
| 구성 | 디스크 3장 |
| 화면 | SCREEN 5 |
| 최소 요구사양 | MSX2 RAM 64KB VRAM 128KB |
최소 요구사양은 거의 모든 MSX2 게임들과 동일하다. 또한 이 게임은 한자를 사용하지 않고 가나 문자만 사용하며 따라서 대사의 고유코드 역시 1byte 이다. 결국 가나 문자만 사용하는 고전 게임들 중 대부분이 그렇듯이 코드 수정으로 폰트를 확장하거나 또는 반조합형 폰트와 극한의 말줄임을 동원해야 한다.
그러나 폰트 확장에 있어서 문제가 되는 것은, 지난 번 포스트에서도 짧게 언급했었지만 플로피 디스크 게임의 폰트 확장에는 난점이 많다. 현재 한식구 등에서 종종 올라오는 폰트 확장 작업들은 거의 모두 롬 카트리지 게임(FC, SFC, GB, GBA 등)에서의 폰트 확장이다. 롬 카트리지는 접근 속도가 매우 빠르므로 완성형 폰트를 롬에 삽입하고 게임에서 로드하는 것에 별 문제가 없다. 또한 당연하게도 롬 카트리지는 (뱅킹이든 아니든) 롬의 모든 영역에 빠른 접근이 가능하고, 롬 확장도 매우 간단하다.
반면에 디스크 게임은 롬 카트리지의 모든 장점이 사라진다. 우선 디스크는 롬과 달리 CPU 가 어드레스 디코더를 통해 특정 주소 공간에 매핑하는 것이 아니므로 디스크의 데이터는 항상 RAM 에 올려진 상태로만 읽을 수 있다. 롬의 경우 롬 영역이 특정 주소 공간에 매핑되고 이를 그대로 읽고 쓰거나 실행까지 바로 할 수 있으나, 디스크는 당연히 이렇게 할 수 없고 디스크 게임을 시작하는 것조차 MSX 표준상으로 0번 섹터를 읽고 RAM 의 주소 0xC000 에 로드한 다음 0xC01E 를 PC 로 설정하는 초기화 작업을 하므로 실제 실행되는 코드는 결국 RAM 에서 실행된다. 즉 디스크에 아무리 많은 용량의 빈 공간이 있어도, RAM 공간이 부족하면 무의미하다.
만약 RAM 에 한글 완성형 폰트 등을 계속 상주시키지 않고 한 글자를 출력할때마다 매번 읽는다고 가정한다면 이론상 문제는 없다. 그러나 이 경우 디스크의 느린 읽기 속도가 발목을 잡는다. 따라서 글자 하나를 출력할때마다 플로피 디스크를 읽는다는 건 현실적으로 불가능하다. 물론 에뮬레이터의 경우 이론적으로는 이 문제를 없앨 수 있지만 그런 제약을 두는 것은 바람직하지도 않고 지향하지도 않는다.
그리고 대부분의 MSX2 게임들이 그렇듯이 이 게임도 최소 사양인 64KB 의 RAM 을 나름 알뜰하게 사용하므로 완성형 폰트 전체를 상시 유지할 만한 여유 공간은 없다. 결국 롬 카트리지 게임과는 근본적으로 다른 방식을 필요로 한다.
이전 포스트에서 프린세스 메이커 작업을 했을 때도 코드를 위한 공간을 별도로 확보했는데, 이 때는 수확제 동안만 임시로 적용하는 것이어서 별 문제가 되지 않았으나 이번처럼 게임 내내 상시 유지해야 하는 코드는 정말 안 쓰이는 영역이 맞는지 확인하고 신중하게 공간을 확보해야한다. 만약 64KB 의 RAM 공간을 거의 다 써서 공간이 없을 경우, 게임 코드 및 전역 데이터에서 불필요하거나 압축 등으로 줄일 수 있거나 하는 부분을 찾아서 최적화하는 등 여러가지 방법으로 억지로 빈 공간을 만들어야 하는데 이는 상당히 까다롭다.
물론 Main RAM 뿐만 아니라 VRAM 이라는 선택지도 있지만, VRAM 은 더더욱 여유 공간이 없는 경우가 많다. 코드를 완전히 개조해서 VRAM 사용을 최적화해야 하는데 이 역시 RAM 에 빈 공간을 만드는 것만큼이나 까다롭다.
결국 가나 문자만 사용하는 MSX 디스크 게임에서는 대부분 폰트 확장을 아무런 리스크 없이 깔끔하게 하는 것은 현실적으로 거의 불가능하다. 그렇다면 리스크를 감수하고 타협을 한다면 어떤 방식이 가능할지 일부 나열해보면 아래와 같다.
-
게임을 거의 처음부터 만드는 수준으로 마개조를 하여 RAM/VRAM 영역 사용을 최적화해서 완성형 폰트를 상시 유지할 수 있는 공간을 확보하는 방법이 있다. 결과물의 퀄리티와 실기 플레이 등을 생각하면 이론적으로는 가장 좋은 방법이지만, 이는 지극히 까다롭고 시간도 많이 걸리기 때문에 취미성 작업에서 이 정도까지 하는 것은 무리가 많이 따른다.
-
Kanji ROM에서 폰트를 가져와서 출력하도록 게임을 개조하는 방법이 있다. 이렇게 하면 다른 Kanji ROM 을 사용하는 게임들의 한국어화 사례들처럼 한글 폰트를 넣어 수정한 Kanji ROM 을 필요로 하게 된다. 이 방식은 매우 간단하고 쉽기 때문에 작업에 무리가 없으나, 없던 제약을 만드는 것이기 때문에(물론 게임 실행에 에뮬레이터를 쓰거나 또는 실기에서도 추가 하드웨어를 사용하는 경우가 많은 요즘에는 큰 의미가 없는 제약이지만) 개인적으로는 그다지 선호하지 않는 방법이나 일단 간단하면서도 좋은 퀄리티로 한국어화를 할 수 있는 방법이므로 나중에 단순 분석이 아닌 정말로 진지하게 번역 작업을 할 때는 이 방법을 선택하는 것을 고려해볼 수는 있을 것이다. 이와 비슷하게 추가적인 제약을 만드는 방식으로는 가령 최소 RAM 요구사양을 128KB 등으로 잡아서 남는 RAM 공간을 이용하는 방식도 있을 수 있다.
-
위에서도 언급한 반조합형 방식이 있다. 이는 이러한 상황에서 현실적으로 가장 많이 사용되는 대표적인 방식이고, 사실 롬 카트리지 게임이나 PC 게임이라고 해도 코드 수정을 통한 폰트 확장을 할 관련 지식이 부족하거나 또는 번거롭게 생각하는 사람들이 많기 때문에 롬 카트리지 게임을 포함해서 종류 불문하고 반조합형은 자주 사용되고 있다. 그러나 서두에 적었듯이 이 분석 작업은 일단 기술적 흥미를 위해 하는 것이므로 반조합형을 사용하지는 않을 것이다. 또한 반조합형은 일단 대사 초벌 번역을 어느 정도 하고나서 말줄임 후 필요한 폰트를 골라서 삽입해야 하는데, 나에게 번역 능력이 없고 번역가분도 없는 현 상황에서는 번거롭다. 게다가 이 게임은 대사량이 상당히 많은 편이라 반조합형으로도 공간적 여유가 없을 가능성도 있다.
-
조합형을 직접 구현하는 방식이 있다. 한글 초/중/종성 자모 폰트만 삽입하고 출력할 때 이들을 조합해서 출력하는 것이다. 이는 Kanji ROM 에서 폰트를 가져오도록 하는 방식보다는 구현이 상당히 복잡해지지만, 게임이 아무런 추가적인 사양을 필요로 하지 않도록 깔끔하게 만들 수 있다는 장점이 있다. 그리고 추가로, 별로 의미가 있는 장점은 아니지만 현대 한글의 모든 글자인 11,172자를 모두 표현할 수 있게 되어서 기존에 한국어화에 보통 사용되던 완성형 2,350자에서 표현하지 못 하는 글자도 표현할 수 있게 된다. 단점으로는 아무래도 미리 만들어진 완성형 폰트에 비해서는 폰트가 미려하지 않을 수 밖에 없다.(물론 반조합형보다는 낫겠지만) 한글 자모의 모양이 글자 조합마다 달라야 가독성이 좋은 한글의 특성상, 자모 하나에 대해서 모양만 다른 폰트를 중복해서 어느 정도 넣고 처리를 해주어야 보기 괜찮은 글꼴이 되고 이는 다다익선인데, 순수하게 초성 중성 종성 1벌만 해도 67개나 되기 때문에 그러기에는 공간이 부족하다. 그래서 이것도 어느 정도 타협을 하고 추가적인 다른 기법이 요구된다.
위와 같이 다양한 방식이 있을 수 있다. 사실 실기에서의 플레이를 포기하고 에뮬레이터를 수정해서 슬롯에 한글 폰트가 있는 ROM 이 들어가도록 하거나 그 외에도 온갖 비표준적 방법을 동원한다면 어떤 플랫폼의 어떤 게임이든 대부분의 기술적 문제는 전혀 문제가 되지 않지만, 개인적으로는 최대한 실기에서 기존과 동일한 환경으로 플레이를 할 수 있는 것을 지향하기 때문에 이 글에서는 4번의 조합형 구현 방식을 시도할 것이다. 다만 만약 나중에 실제 한국어화 작업을 하게 된다면 Kanji ROM 을 사용하는 방식까지 투 트랙으로 진행해서 번역된 대사 데이터 하나만으로 둘 모두에 호환이 되도록 하는 것을 생각하고 있다.
Pre-analysis
우선 폰트의 위치를 확인하기 위해 VRAM 을 확인해보면 아래와 같다.
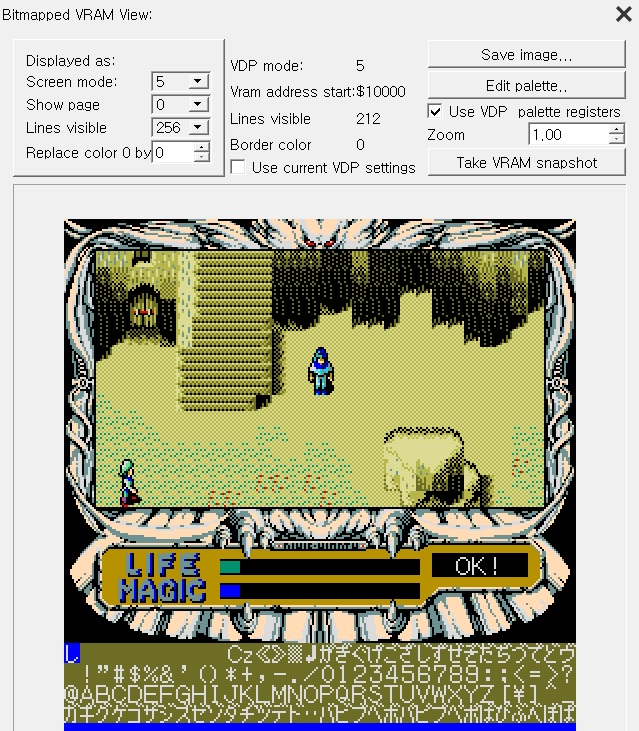
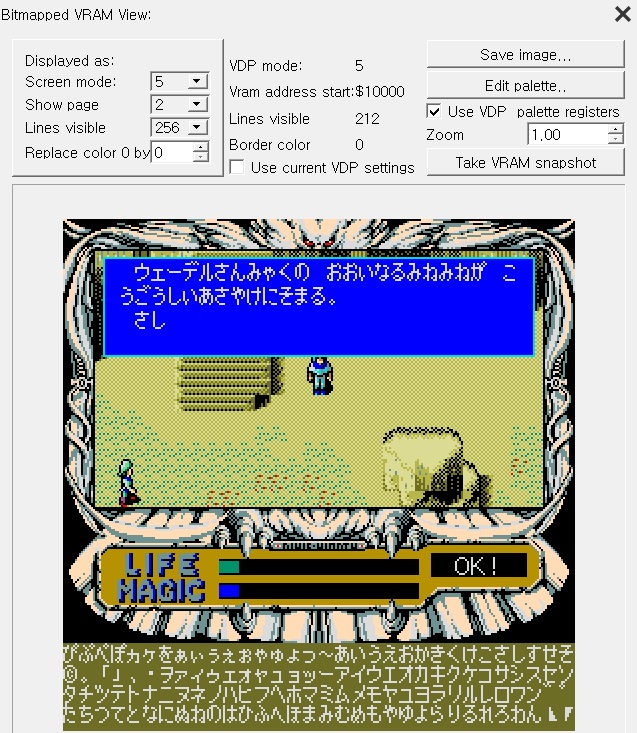
MSX 에서 SCREEN 5 는 VRAM 공간을 4개의 Page 로 나누는데, 한 Page 는 32KB(0x8000) 이다. 또한 16색 팔레트에서 색을 선택하므로 한 픽셀당 4bit(4bpp)로 구성되는데, 결과적으로 가로 256픽셀은 128bytes 를 차지한다. SCREEN 5 의 해상도는 256x212 이므로 화면 전체가 차지하는 용량은 128x212 = 27136bytes(0x6A00) 가 된다. 즉 한 Page 에서 화면의 픽셀 데이터(Pattern name table)를 제외하고 0x8000 - 0x6A00 = 0x1600 의 공간이 남게 된다.
위 이미지에서 폰트가 들어있는 공간은 이 0x1600 의 남는 공간에 각각 폰트를 나누어 넣은 것이다. Page 0 과 Page 2 는 둘 다 Pattern name table 이 위치하는데, 많은 게임들이 그렇듯이 게임상에서는 필요에 따라 적절히 둘 중 화면에 실제로 출력될 Page 설정을 바꿔준다. 룬워스는 대부분의 시간 동안 Page 2 가 출력되는 것으로 생각된다.
보다시피 일단 공간에 여유는 당연히 없다. 또한 Page 0 의 폰트 영역 시작 부분은 폰트가 저장되는 곳이 아니라 매번 한 글자를 출력할때마다 출력하는 곳에 맞게 폰트의 배경 및 전경색을 바꿔서 임시로 저장하는 공간이다.
그리고 VRAM 의 Page 3 에는 정체를 알 수 없는 데이터가 있는 것을 확인할 수 있다.
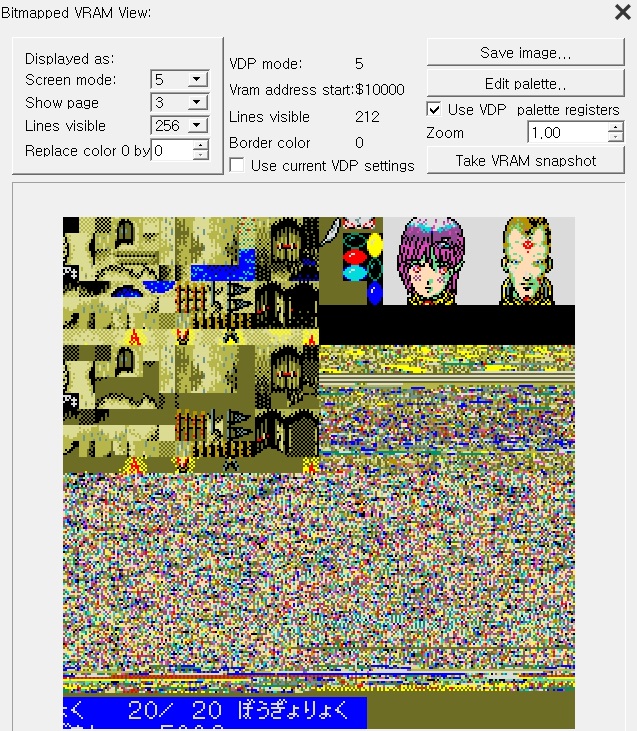
저 영역의 데이터가 언제 어떻게 변경되는지 디버거로 확인해보려고 했으나 번거롭게도 openMSX debugger 는 Break 되었을 때만 VRAM 뷰어를 업데이트하고 실행 중에 실시간으로는 업데이트를 하지 않는다. 그래서 디버거 코드를 살짝 수정해서 0.5초 간격으로 계속 갱신해주도록 하고 빌드해서 확인해보았다.
위처럼 맵 이동이 발생할 때 아래쪽 데이터가 통째로 바뀌는 것으로 보인다. 저 데이터가 무엇인지는 분석을 해봐야 알 수 있을 것이다. 이는 뒤에서 텍스트 출력을 분석하면서 알아보도록 한다.
우선 이렇게 코드 분석을 처음 시작할 때, 어디서부터 시작해야 할지 막막하게 생각할 수 있을 것이다. 정답은 없으나 내가 MSX 게임을 분석할 때 주로 사용하는 방법 중 하나는 일단 텍스트 출력 루틴을 찾는 것으로 시작한다. MSX 에서 폰트를 화면에 출력하는 과정은 한 가지가 아니라 여러가지가 있다. 게임에 따라 어떤 방식을 사용할지는 다 다르므로 모두 시도해보아야 한다.
크게 보면 우선 첫 번째로 VDP 커맨드를 이용하는 방법이 있다. MSX2 는 다양한 VDP 커맨드를 지원하는데 이는 빠른 속도로 화면에 무언가를 복사하거나 할 때 적합하고, 논리 연산도 지원하는데 이는 폰트처럼 투명색이 있는 듯 취급해서 글자 부분만 다른 배경색에 복사하거나 할 때 적절하게 사용할 수 있다. VDP 커맨드처럼 특수한 연산은 추적하는 것이 매우 쉽다는 장점이 있다.
그리고 두 번째로 VRAM 에 직접 일일이 쓰는 방법이 있다. 이는 특성상 추적을 위해서는 어셈블리 레벨에서 가능한 명령어가 여러가지로 나뉘는데, 여러 게임들을 분석해보면 게임에 따라 다양한 방식이 쓰이는 것을 알 수 있다. 몇 가지 예를 들면 아래와 같다.
- out (c), reg
- out (#98), a
- outi
- otir
어찌됐든 결과적으로 VRAM 에 쓰기 위해서는 out 을 하기 때문에, 위는 단지 형태만 다를 뿐 결과적으로 동일한 명령들이다. 이러한 명령어들이 사용되는 것을 추적하면 된다. 방식은 이전 포스트에서 jp 명령어를 로깅했던 것과 별반 다르지 않다.
여기서는 일단 VDP 커맨드 사용을 로깅해보자. openMSX 에뮬레이터의 src/video/VDPCmdEngine.cc 소스 코드에서 포스팅하는 시점 기준으로 1804번째 라인에 있는 VDPCmdEngine::setCmdReg 함수를 보면 아래와 같다.
void VDPCmdEngine::setCmdReg(byte index, byte value, EmuTime::param time)
{
sync(time);
if (CMD && (index != 12)) {
cmdInProgressCallback.execute(index, value);
}
switch (index) {
case 0x00: // source X low
SX = (SX & 0x100) | value;
break;
.....
case 0x0E: // command
CMD = value;
executeCommand(time);
break;
default:
UNREACHABLE;
}
}
VDP 커맨드를 실행하기 위해서는 다양한 VDP 커맨드 레지스터를 설정하게 되는데, 이 중에서 Register 46 에 값을 쓰는 작업이 곧 VDP 커맨드를 최종적으로 실행하는 것이다. openMSX 코드 기준으로는 index 가 0x0E 인 레지스터가 Register 46 을 의미한다. 따라서 이 때 여러 VDP 커맨드 레지스터의 값을 기록하면 VDP 커맨드 실행을 완전하게 추적할 수 있다. 그래서 적당히 코드를 아래와 같이 추가해준다.
case 0x0E: // command
{
FILE *fp = fopen("setting.txt", "r");
if( fp != NULL ){
fclose(fp);
fp = fopen("vdpcmd.txt", "a");
fprintf(fp, "CMD=%02X SX=%d SY=%d DX=%d DY=%d NX=%d NY=%d\n", value, SX, SY, DX, DY, NX, NY);
fclose(fp);
// Sleep(1000);
}
CMD = value;
executeCommand(time);
break;
}
default:
UNREACHABLE;
}
}
VDP 커맨드는 텍스트 출력이 아니더라도 사용될 수 있고, 끊임없이 기록하면 헷갈리고 번거로울 수 있으므로 편의상 setting.txt 라는 텍스트 파일이 존재할 때만 기록하는 것으로 한다. 그러면 텍스트 출력 시점에 적당히 breakpoint 를 걸어놓고 setting.txt 파일을 생성한 다음 실행하면 된다. 또한 로그를 확인해보고 이 게임이 VDP 커맨드를 이용해 글자를 출력하는 것이 맞다면, 그 코드 위치를 찾기 위해 위 소스에 있듯이 1초 정도 Sleep 을 걸어주면 한 글자가 출력될때마다 1초씩 멈추게 되는데 이 때 break 를 누르면 1초 뒤 정확히 VDP 커맨드 레지스터에 값을 쓴 직후(out 한 직후)의 어셈블리 코드에서 break 가 걸리게 되어 위치를 쉽게 찾을 수 있다.
그래서 위에 서술한 대로 적당히 대사를 출력중인 시점에 기록된 로그를 보면 아래와 같다.
CMD=C0 SX=0 SY=222 DX=0 DY=212 NX=8 NY=10
CMD=98 SX=152 SY=734 DX=0 DY=212 NX=8 NY=10
CMD=83 SX=152 SY=744 DX=0 DY=212 NX=8 NY=10
CMD=D0 SX=0 SY=212 DX=36 DY=533 NX=8 NY=10
CMD=C0 SX=0 SY=222 DX=0 DY=212 NX=8 NY=10
CMD=98 SX=128 SY=734 DX=0 DY=212 NX=8 NY=10
CMD=83 SX=128 SY=744 DX=0 DY=212 NX=8 NY=10
CMD=D0 SX=0 SY=212 DX=52 DY=533 NX=8 NY=10
보면 4개의 VDP 커맨드가 반복되고 있는 것을 볼 수 있다. CMD 값은 하위 4bit 는 논리 연산이므로 상위 4bit 로 종류를 알 수 있는데, 각각 HMMV(Cx), LMMM(9x), LMMV(8x), HMMM(Dx) 이다. 이게 어떤 동작인지를 분석하려면 옆의 VDP 커맨드 레지스터 값들을 봐야 하는데, 이름 그대로 SX/SY 는 Source 이고 DX/DY 는 Destination 이다. 이 값들은 VRAM 을 픽셀 기준 위치로 표현하는 좌표이다. 그리고 NX/NY 는 Size 인데, 8x10 이라는 크기는 글자 하나의 폰트 크기라는 것을 쉽게 추측할 수 있다. 이 좌표값들로 VRAM 뷰어에서 해당 위치에 무엇이 위치하고 있는지를 보면서 동시에 각 VDP 커맨드가 어떤 동작인지를 같이 분석하면 쉽게 파악할 수 있다.
- Page 0 의 (0, 212) 위치부터 8x10 영역을 특정 색상으로 채운다.
- Page 2 의 (152, 222) 위치에 있는 8x10 영역을 Page 0 의 (0, 212) 위치로 복사한다. 이 때 논리 연산으로 8 이 설정되었는데, 이는 TIMP 연산으로 팔레트의 0번 색상인 부분은 복사를 하지 않는 연산이다. 말하자면 0번 색상이 투명색이 되는 것으로 생각할 수 있다.
- Page 0 의 (0, 212) 위치부터 8x10 영역을 특정 색상으로 채운다. 이 때 논리 연산으로 3 이 설정되었는데, 이는 EOR 연산으로 말 그대로 원래 위치의 색상과 덮어쓸 색상에 대해 XOR 연산을 한다. 이는 글자가 흰색이 아닌 다른 색상일 때, 글자색을 넣기 위해 VDP 커맨드를 하나 더 호출하지 않고 하나의 커맨드로 배경과 전경색을 동시에 설정하기 위한 용도로 쓰인다. 이를 위해 1번에서 특정 색상으로 채울 때 이 XOR 연산을 감안해서 색상을 채우는 것을 볼 수 있다.(목표 배경색과 3번에서 채우는 특정 색상을 미리 XOR 해서 그 색상을 1번에서 채우는 것이다)
- Page 0 의 (0, 212) 위치에 있는 8x10 영역을 Page 2 의 (36, 21) 위치에 복사한다. 최종적으로 임시 영역에 원하는 색상으로 만들어진 폰트를 실제 게임 화면에 표시하는 것이다. 가령 다음 글자는 (44, 21) 위치에 표시될 것이다.
말이 복잡하지만 그림으로 보면 더욱 간단하다.
우선 위의 (0, 212) 위치가 특정 색상으로 채워진다. (저 파란색은 실제로는 팔레트 5번 색상)

Page 2 의 (152, 222) 위치는 화면 해상도 212 를 빼면 위 이미지 기준으로 (152, 10) 이고, 글자 하나당 가로 길이가 8 이므로 결과적으로 2번째 줄의 20번째(152÷8+1) 글자를 의미하며 빨간색 박스로 표시한 글자가 해당 글자이다. 이 글자를 Page 0 의 (0, 212) 위치로 복사하면 아래처럼 된다.
여기서는 글자가 흰색이라 EOR 연산을 하는 LMMV 커맨드는 아무런 변화를 주지 않는다. 따라서 바로 다음 커맨드인 게임 내 화면에 이 글자 영역을 복사하는 커맨드를 실행한 결과를 보면 아래와 같이 표시된다.

이렇게 하면 한 글자 표시가 완료된다. 이를 대사 출력시에 계속 반복한다.
이제 본격적으로 코드 위치를 찾기 위해, 위에서 얘기했듯이 VDP 커맨드가 실행될 때 짧게 Sleep 을 하도록 코드를 추가하면 그 사이에 디버거에서 break 를 하면 VDP 커맨드 실행 직후의 명령어에서 정지한다고 하였다. 실제로 해보면 아래와 같은 결과를 얻는다.
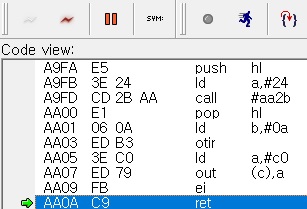
0xC0 을 VDP 커맨드 레지스터에 쓰고 인터럽트를 활성화하는 코드가 보이는데 이는 정확히 HMMV 커맨드를 실행하는 루틴임을 알 수 있다. 그러면 이제 이 부분을 디스크 파일에서 헥스 에디터로 찾아서 IDA 로 열어보면 된다. 이전 포스트에서 서술했던 것과 방식은 동일하다.

위와 같이 2번 디스크에서 해당 코드를 찾을 수 있다. 분석하면서 여러 부분에 이름을 지어놓았다. 이제 이 부분을 시작점으로 잡고 디버거의 콜스택과 IDA 의 xrefs 등을 참조해가며 전체적인 흐름을 파악하고 폰트 확장에 필요하다고 생각되는 부분들을 쭉 분석하면 된다.
또한 이러한 방법 외에도 이전 포스트에서도 서술했지만 디스크 읽기를 추적하는 방법도 있다. 룬워스에서 처음 게임을 시작하기 위해 Start Disk -> User Disk -> Game Disk A 를 차례로 넣게 되는데, Game Disk A 를 넣고나면 첫 대사 출력이 시작되므로 Game Disk A 를 넣은 직후의 디스크 읽기를 로그로 남겨볼 수 있다.
B=01 DE=00 HL=4000
B=10 DE=3A HL=8000
B=01 DE=00 HL=4000
B=04 DE=AC HL=A000
B=01 DE=00 HL=4000
B=09 DE=327 HL=5000
B=01 DE=00 HL=4000
B=08 DE=31B HL=4000
B=04 DE=323 HL=4000
B=01 DE=00 HL=4000
B=08 DE=30D HL=4000
B=06 DE=315 HL=4000
B=01 DE=00 HL=4000
B=08 DE=F4 HL=4000
B=08 DE=FC HL=4000
B=06 DE=104 HL=4000
B=04 DE=2AD HL=4000
여기서 0x8000 주소에 로드하는 데이터를 확인해보면 아래와 같다.
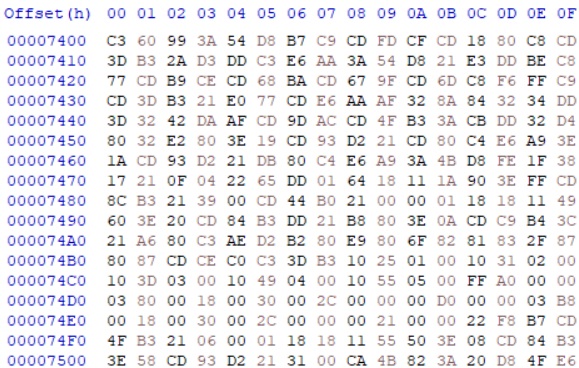
보다시피 Z80 코드인 것을 알 수 있다. 0x8000 에 Breakpoint 를 걸어보면 멈추는 것을 볼 수 있는데, 이 부분을 시작점으로 잡고 분석할 수도 있다. 이렇게 다양한 방법을 이용해서 코드 분석을 하게 된다.
Analysis
이제 본격적으로 폰트 확장을 위한 분석 내용을 서술하도록 한다.
우선 코드를 분석하다보면 텍스트를 어디서 가져오는지 알 수 있는데, 위에서 설명한 VRAM 의 Page 3 에 있는 정체불명의 데이터가 대사 텍스트라는 것을 알 수 있다. 이를 직접 확인하기 위해 일단 코드 테이블을 만든다. 양이 적으니 금방 만들 수 있다.
00=♨
...
91=あ
92=い
93=う
...
FA=れ
FB=ろ
FC=わ
FD=ん
FE=◣
FF=◤
VRAM 덤프는 openMSX 에서 Save State 로 상태 저장을 할 때 만들어지는 oms 파일에서 추출하는 방법이 있다. 이를 위해 간단히 oms 파일에서 vram 데이터를 추출하는 스크립트를 만들면 된다.
import sys
import zlib
import gzip
import base64
import xml.etree.ElementTree as ET
def getvram(filename):
f = gzip.open(filename).read()
root = ET.fromstring(f)
for f in root.iter("vram"):
if f.find("data") != None:
b64 = bytes(f.find("data").text, "ascii")
return zlib.decompress(base64.decodebytes(b64))
def main():
if len(sys.argv) < 2:
print("Usage: python3 getvram.py savestate.oms vram.bin")
return
vram = getvram(sys.argv[1])
open(sys.argv[2], "wb").write(vram)
if __name__ == "__main__":
main()
이제 VRAM 을 덤프하고, 정체불명의 데이터가 시작하는 위치인 0x1C000 부터 코드 테이블을 이용해 표시해보면 아래와 같다.
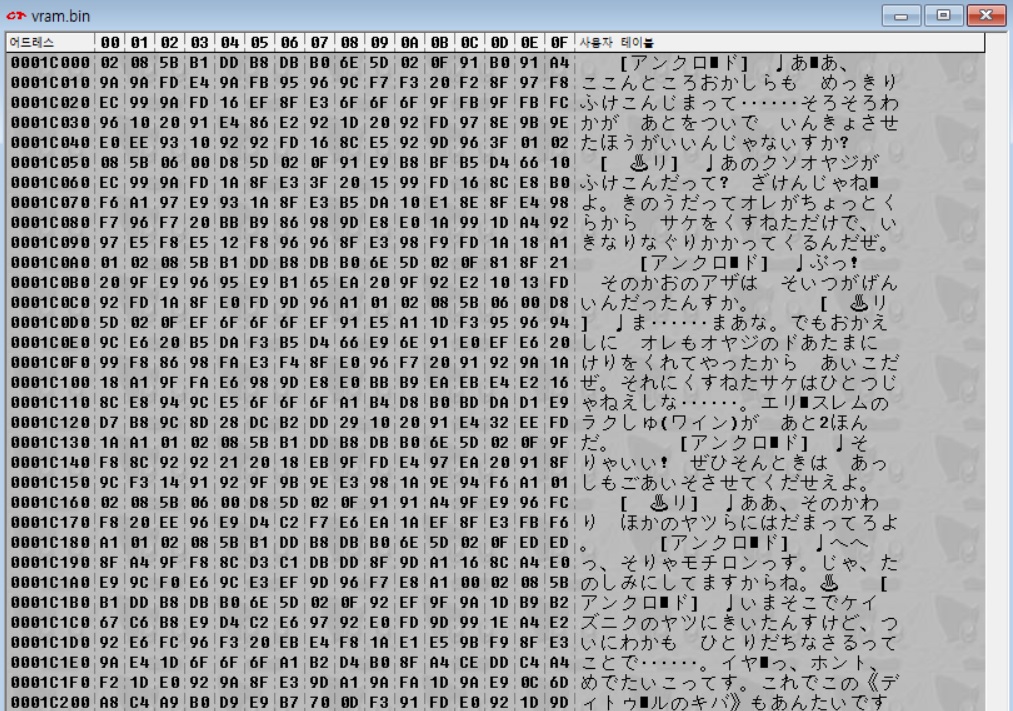
올바른 일본어로 생각되는 대사들이 표시되는 것을 알 수 있다. 즉 디스크에 있는 대사를 VRAM 으로 복사해놓고, 출력할 때 VRAM 에서 가져와서 사용하는 것이다. 그리고 위에서 이 부분은 맵 이동을 할 때마다 통째로 바뀐다고 하였는데, 아마도 해당 맵에서 사용하는 모든 대사가 들어있는 것으로 추측할 수 있다. 처음 맵에서만 대사량이 0x3000 으로 12KB 라는 상당한 양이다. 만약 64KB 의 RAM 에 이 대사 데이터가 상주하도록 했다면 RAM 의 거의 1/5 를 대사만으로 채웠을 것이다.
그러면 이제 폰트 확장을 위해 중요한 루틴 몇 가지를 분석해보자.
1. print_text 함수(0xB044) - Game Disk A 오프셋 0x3055
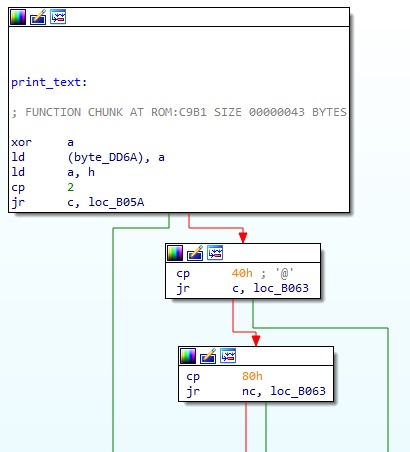
이 함수는 print_text 로 명명했듯이, 대사를 출력하는 함수이다. 당연히 한국어화에 있어서 가장 중요한 함수일 것을 짐작할 수 있다. 인자로 받는 hl 레지스터는 대사를 가리키는 값이고 bc 레지스터는 출력을 시작하는 좌표값인데, hl 레지스터의 값을 어떻게 해석하고 어디서 가져오는지는 대략 3가지로 경우로 나뉜다.
- hl 레지스터를 미리 만들어진 주소 테이블의 index 로 사용해서 새로운 주소를 가져오고 이를 메인 RAM 상의 주소로 생각해서 문자열을 가져온다.1 이는 대부분 대사를 제외하고 게임 내에 표시되는 여러 문자열들을 가져올 때 사용한다.
- 유저가 임의로 설정하는 캐릭터 이름 등 가변적인 데이터를 가져온다. 과정은 1번과 거의 공유하지만 이 경우는 hl 의 주소가 현재 주소 공간 기준의 주소이므로 RDSLT 을 사용할 필요도 없이 바로 읽어서 출력한다.
- hl 레지스터의 값을 VRAM 상의 주소를 가리키는 간단한 포맷으로 생각하여 VRAM 에서 대사를 가져와서 출력한다. 가령 0x4000 이면 VRAM 상에서 0x1C000 주소를 가리키는 것으로 생각하면 된다.
이 함수는 대사에 제어코드 00 이 나올 때까지 계속 출력한다. 또한 대사에 제어코드로 유저가 설정하는 캐릭터 이름 등 가변적인 데이터 출력을 요구하는 코드가 있을 경우 재귀적으로 print_text 함수 내에서 print_text 를 또 호출하여 캐릭터 이름을 출력하고 다시 돌아와서 이어서 대사를 계속 출력하는 식으로 이루어진다.
위에서 서술한 모든 경우를 생각해서 대사의 문자 하나를 가져오는 함수는 아래와 같다.
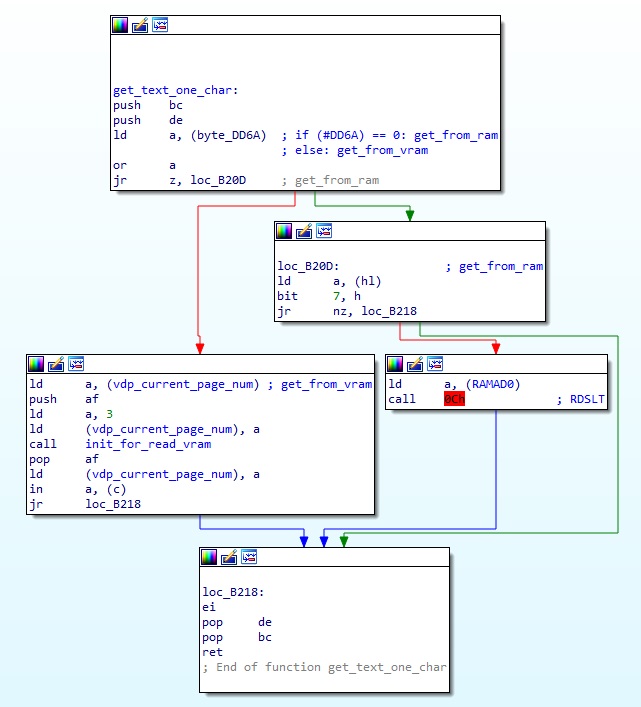
이 함수는 print_text 내에서 여러 번 호출된다. 특히 제어코드의 경우 00, 01 을 제외하면 모두 1byte 가 아니라 2bytes 이상으로 구성되기 때문에 최소 2번 이상 호출된다. 물론 print_text 함수 내에는 문자를 읽어서 제어코드인지 아닌지 확인하는 루틴도 있는데 다음과 같다.
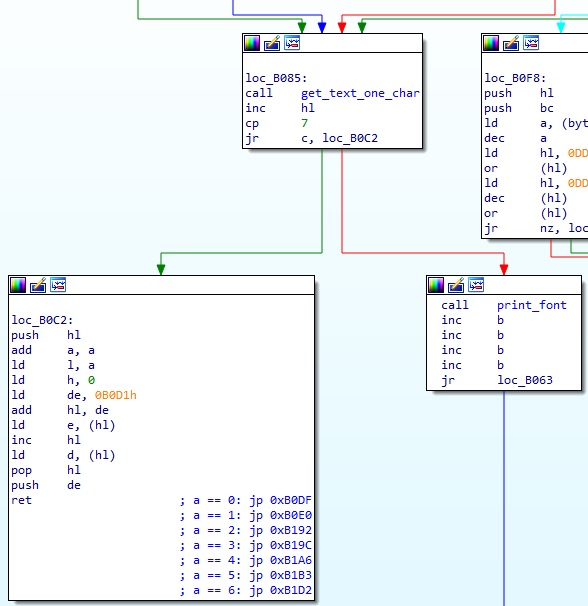
보면 읽은 문자 코드가 7 보다 작은지를 체크해서 분기를 하고 있는데, 즉 제어코드가 00 ~ 06 까지 있다는 것으로 생각할 수 있다. 7 이상의 코드는 그대로 print_font 함수로 진행해서 해당 코드에 맞는 글자를 바로 출력한다. 제어코드의 경우 위 이미지의 아래쪽에 주석으로 적어놨다시피 제어코드에 따라 각각 정해진 핸들러로 점프한다. 00 은 종료 제어코드인 만큼 그냥 바로 ret 로 print_text 에서 종료할 뿐이고, 02 부터는 코드가 연속적으로 존재하므로 확인해보면 아래와 같다.
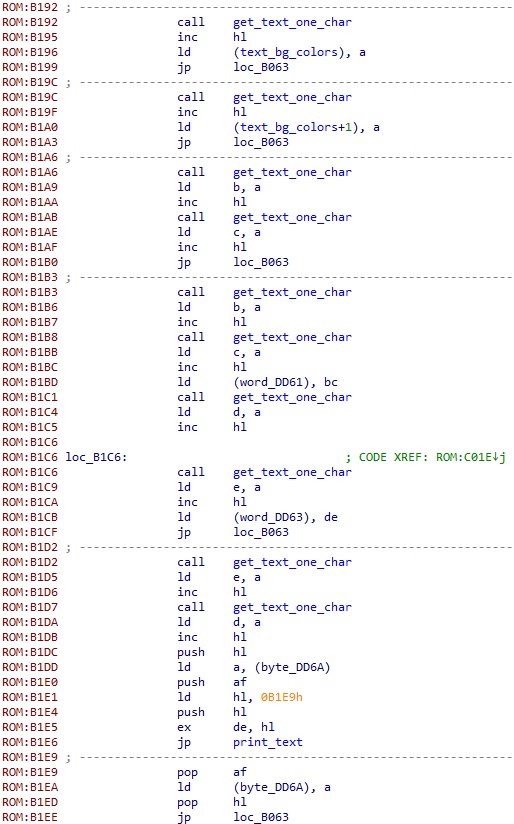
text_bg_colors 는 다른 쪽을 분석하면서 명명한 것인데, 여기에서 쓰는 것으로 보아 대략 제어코드 02 와 03 은 텍스트 색상 설정과 관련이 있는 것으로 추측할 수 있다. 또한 마지막의 제어코드 06 핸들러 부분에 print_text 를 호출하는 것을 볼 수 있는데, 이것이 위에서 잠시 설명한 대로 유저가 설정한 캐릭터 이름 등의 가변적인 텍스트를 출력하는 제어코드이다.
2. print_font 함수(0xB08D) - Game Disk A 오프셋 0x309E
위의 print_text 함수 루틴 이미지에서 살짝 나왔듯이, 이는 print_text 함수에서 호출되며 실제로 폰트를 화면에 출력하는 함수이다.
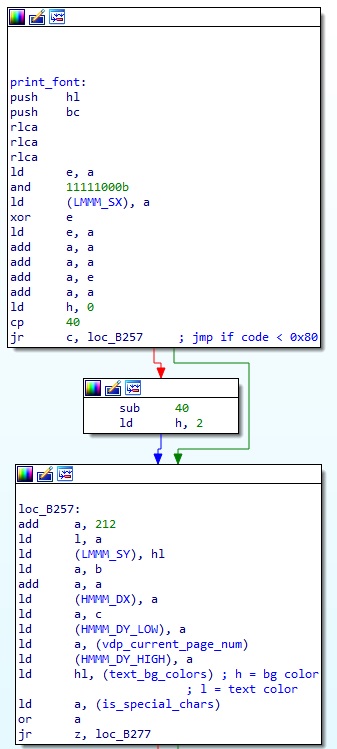
대사 코드 1byte 를 a 레지스터를 통해 인자로 받아서 이를 이용해서 대사 코드에 맞는 폰트의 위치를 찾는다. 위에서 VDP 커맨드로 폰트를 출력하는 과정을 다시 확인해보면, LMMM 커맨드는 특정 위치에 있는 폰트를 Page 0 의 (0, 212) 위치로 복사한다고 했다. 원본 폰트를 복사하는 것은 이 작업이 유일하므로, 위 이미지에서 보다시피 a 레지스터로 받은 대사 코드를 이용해서 원하는 폰트가 있는 오프셋을 계산하고, 이를 LMMM_SX 와 LMMM_SY 로 명명한 변수에 값을 설정한다.
그리고 뒤에서는 아래와 같은 작업을 한다.
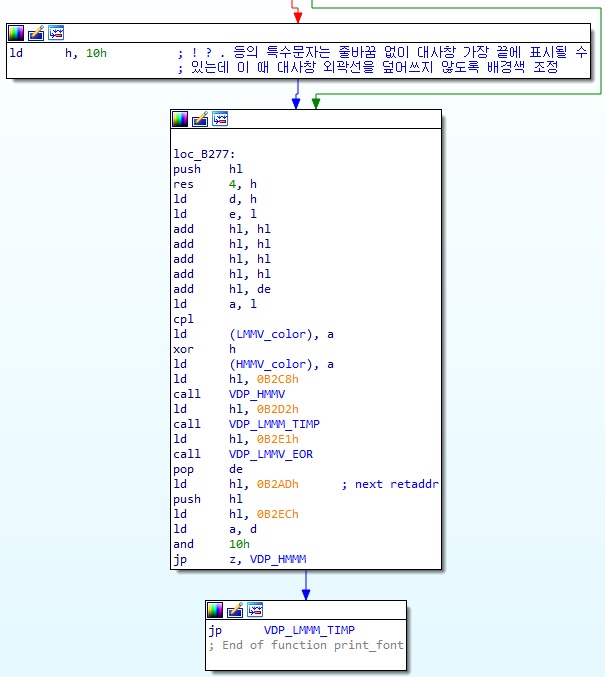
보다시피 앞에서 VDP 커맨드 로깅으로 분석한 내용과 정확히 일맥상통하는 코드가 있는 것을 볼 수 있다. HMMV -> LMMM -> LMMV -> HMMM or LMMM 이라는 순서로 커맨드를 실행하고, 이 작업도 앞에서 분석한 내용과 동일하다.
3. VDP 커맨드 실행 함수
VDP 커맨드 실행 함수들 자체는 사실 특별한 점이 없으나, 함수의 시작이 두 가지로 나뉘어지는 경우가 있다. 예로 HMMM 커맨드를 실행하는 함수를 보자.
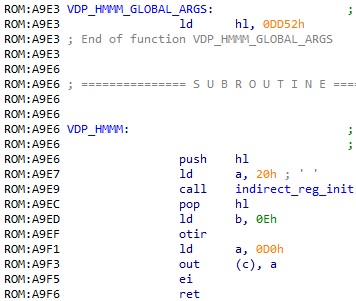
VDP_HMMM 이라고 명명한 위치와 별개로, 바로 위에 VDP_HMMM_GLOBAL_ARGS 로 명명한 위치의 심볼이 별개로 존재한다. 만약 VDP_HMMM 을 call 하는 경우에는 hl 레지스터를 인자로 받아서 이 hl 이 가리키는 메모리 주소에 있는 값들을 그대로 VDP 커맨드 레지스터 설정에 사용한다. 그러나 VDP_HMMM_GLOBAL_ARGS 을 call 하면 hl 이 고정 주소로 설정된다. 따라서 이 둘의 xrefs 를 별개로 확인해서 나중에 찾기를 원하는 커맨드 실행이 어디에서 시작하는지 알아야 할 필요가 있다.
물론 위처럼 hl 을 0xDD52 로 설정하면, 이 주소에 VDP 커맨드 레지스터 설정에 필요한 값들을 미리 설정해둔 다음 호출할 것이다. 실제로 xrefs 를 확인해보면 가령 print_text 함수에서 대사 스크롤을 담당하는 루틴에서 이렇게 0xDD52 주소에 여러 값을 설정한 다음 호출을 하는 것을 확인할 수 있다.
Scenario
이제 한국어화를 위해 필요한 몇 가지 내용을 미리 구상해보도록 한다. 우선 조합형 폰트부터 시작한다.
Font
본격적인 한국어화 작업에 들어가기 전에, 조합형 폰트를 어떻게 구성할지에 대해서 미리 생각하고 테스트를 해야한다. 어셈블리로 코드를 작성하기 전에 미리 Python 으로 알고리즘을 만들어놓아야 편하게 작업할 수 있을 것이다. 일단 초성/중성/종성 폰트 1벌을 준비한다.
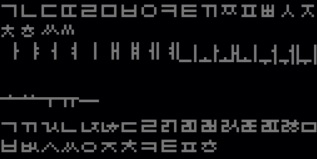
위는 사실 최종 결과물이고, 원래 처음에는 자연스럽게 ㄱㄴㄷㄹㅁㅂ… 같이 정상적인 순서로 배치해서 테스트를 했으나 왜 저런 배열로 구성했는지는 후술하도록 한다.
우선 원래 룬워스의 폰트 사이즈는 8x10 이고, 게임도 당연히 이에 맞춰서 만들어져있다. 그러나 8x10 으로 조합형 한글을 구성하면 퀄리티가 크게 떨어지기 때문에 8x12 로 늘리는 개조 작업을 이후에 하기로 하고 우선 조합형 폰트는 8x12 가 되도록 구성한다. 그러면 일단 위의 초성 중성 종성을 별 다른 처리 없이 그대로 합쳐보면 아래와 같다.

당연하게도 폰트가 제대로 구성되지 않는다. 서두에서도 언급했듯이 조합형 폰트는 보통 초/중/종성의 조합에 따라서 다른 폰트를 사용해야 좋은 결과물을 얻을 수 있다. 그냥 합치면 위와 같이 제대로 된 결과를 얻을 수 없다. 여기서 테스트한 초성 폰트의 경우 중성이 “ㅗ”, “ㅛ” 등일 때 잘 맞는 위치이므로 “고” 나 “곡”, “곱” 등은 잘 나오는 것을 볼 수 있다.
그러나 일단 공간 부족으로 인해 이 1벌 외에 다른 폰트를 더 추가하지는 않을 생각이므로, 별도로 퀄리티를 조금이나마 개선하는 알고리즘이 필요하다. 그래서 우선 간단한 휴리스틱을 생각하기로 했고 먼저 아래와 같은 함수를 고안했다.
def shift(font, w = [], h = []):
result = ""
for i in range(len(font)):
flag = 0
for j in range(len(h)):
if i == h[j]: flag = 1
if flag == 1: continue
t = ord(font[i])
const1 = [0b1, 0b11, 0b111, 0b1111, 0b11111, 0b111111, 0b1111111, 0b11111111]
for j in range(len(w)):
a = const1[w[j]]
t2 = t & a
t -= t2
t += (t2 << 1) & a
result += chr(t)
return result.ljust(16, "\x00")
이 함수는 가로와 세로에 대해서 각각 주어진 특정 line 을 없애고 왼쪽으로 붙이는 간단한 작업을 수행한다. 말이 복잡하니 간단하게 이미지로 보면 아래와 같다.
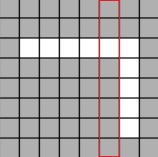
위와 같은 글자를 비트로 생각해서, 가장 오른쪽 줄은 0번째 비트이고 빨간색 박스는 2번째 비트가 된다. 이 때 위의 함수에서 가로 2번째를 제거하는 작업을 한다면 w 인자에 [2] 를 보낼 것이다. 이렇게 하면 수행 결과는 아래와 같다.
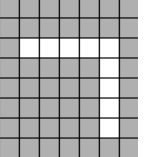
이런 식으로 원하는 위치의 줄을 제거하는 작업을 한다. 물론 가로줄도 없앨 수 있다. 가로줄은 결국 1byte 값 하나를 의미하므로 아예 append 작업 시에 해당 byte 자체를 생략하는 식으로 간단하게 구현된다.
이제 위에서 초/중/종성 폰트의 배열이 이상했던 이유를 말할 수 있다. 바로 이 조정 작업을 동일하게 할 수 있는 자모에 대해 최대한 코드를 중복해서 쓰지 않고 간단한 조건문 검사만으로 한 번에 처리할 수 있게 하기 위해서이다. 이는 어셈블리 코드로 변경해야 한다는 것을 생각해보면 시간 절약 및 코드의 복잡성을 줄이기 위해서라도 의미가 있다.
이 조정을 어떻게 할지는 특별히 정해진 것도 없고 이리저리 해보면서 결정했다. 이것도 물론 최적일리는 없으나 적당한 가독성이 나올 만큼만 진행했다. 그래서 만든 알고리즘은 아래와 같다.
if jung < 16:
if cho < 11: f1 = shift(f1, [2, 5, 7])
elif cho < 13: f1 = shift(f1, [3, 7])
elif cho < 18: f1 = shift(f1, [7])
else: f1 = shift(font_cho[cho+1], [7])
if jung > 8:
if jong != 0:
f1 = shift(f1, h=[0])
f2 = shift(f2, h=[0])
else:
f1 = shift(f1, h=[0])
if jung > 17:
if jong != 0:
f2 = shift(f2, h=[0, 10])
font = ""
for i in range(16):
font += chr(ord(f1[i]) | ord(f2[i]) | ord(f3[i]))
fonts += font
위의 폰트 이미지에도 나와있지만, ㅆ 의 경우 이 방식으로는 한계가 있어서 어쩔 수 없이 다른 모양의 초성 1글자를 마지막에 추가하고 위 조건문에서 font_cho[cho+1] 같은 식으로 중성에 따라 다른 모양을 사용하도록 했다. 종성의 경우 그대로 붙여도 별 문제가 없어서 아무런 연산을 하지 않았다.
이렇게 해서 조합형 폰트를 생성한 결과는 아래와 같다.

꽤 그럴듯한 모양으로 구성되었다. 글자마다 통일성이 없고 좀 오락가락하다는 근본적인 한계는 있지만, 그래도 그리 나쁘지 않은 퀄리티로 구성할 수 있다. 따라서 이 알고리즘을 그대로 게임 내에서의 조합형 구현에 사용할 것이다.
Code
한글 2bytes 조합형 코드를 얘기할 때 가장 먼저 떠올릴 수 있는 방법은 각 초성, 중성, 종성에 일정 비트를 할당해서 구성하는 방식이다. 이는 한글 상용 조합형 인코딩에서도 사용되었던 방법이며 2bytes 코드에서 각 초성 중성 종성 코드를 분리하는 것도 단순히 시프트만 하면 되므로 매우 간단하다.
이 방식을 사용해도 되지만, 좀 재미로 다른 방식을 사용했다.
초성 중성 종성에 각각 정해진 비트를 할당하는 게 아니라, 연속적인 코드를 사용하고 거기서 초성 중성 종성 코드를 각각 분리하는 연산을 별도로 하기로 했다. 이 연속적인 코드의 시작은 물론 아무거나 해도 되지만, 특별히 여기서는 UTF-16, 즉 유니코드를 사용하기로 했다. 유니코드 평면에서 한글은 0xAC00 부터 0xD7A3 까지를 차지한다. 이 코드를 그대로 사용한다.
이러한 연속적인 코드에서 초성 중성 종성을 분리하는 연산은 흔히 알려져있다시피 아래와 같다.
cho = x / (21 * 28)
jung = (x % (21 * 28)) / 28
jong = (x % (21 * 28)) % 28 = x % 28
x 는 0 부터 11,172 까지의 숫자이다. 따라서 0xAC00 을 시작으로 한다면 코드에서 0xAC00 을 뺀 값에 위의 연산을 적용하면 된다. 이렇게 하면 UTF-16 한글 코드를 그대로 사용할 수 있다. 물론 별 의미는 없다.
그리고 이렇게 하면 원래 1byte 영역에서 0xAC ~ 0xD7 을 제외한 다른 영역에 할당되어 있는 특수 문자나 가나 문자 등은 그대로 사용할 수 있다. 또한 고유코드 테이블은 그냥 한글 UTF-16 코드를 그대로 나열하기만 하면 만들 수 있다. 물론 실제 UTF-16 과 달리 특수문자나 제어코드 등에 쓰이는 1byte 코드와 혼용해서 대사를 구성하게 되므로 대사 텍스트를 2bytes 단위로 완전한 UTF-16 파싱을 할 수 있는 것은 아니다.
참고로 Z80 에는 나눗셈 명령이 없으므로 직접 구현해야 하는데, 물론 이는 구글링하면 쉽게 찾을 수 있고 여기에도 나와있으므로 그대로 사용했다.
Patch
Prologue
이제 실제로 코드 패치를 해보도록 한다. 우선 가장 먼저 해야할 일은 어디에 어떻게 코드 패치를 할 것인지를 정해야 한다. 이전 포스트의 프린세스 메이커에서는 수확제 동안에만 처리하는 코드였기 때문에 수확제 시작 부분을 덮어썼지만, 이 게임은 게임 전체에 적용하기 때문에 거의 게임 시작에 가까운 부분을 덮어써야 한다.
룬워스는 처음 Start Disk 를 삽입하고 부팅하면 오프닝 화면이 반복적으로 나오고, 이후 키를 누르면 아래와 같은 화면이 출력된다.

디스크 A 를 넣어달라는 문구가 출력되는데, Game Disk A 를 실제로 삽입한 후 키를 누르면 아래처럼 초기 화면이 출력된다.
여기서부터 실제로 폰트가 로드되고 사용되기 시작한다. 위의 디스크 A 를 넣으라는 문구는 아직 확인해보진 않았으나 아마도 이미지인 것으로 추정된다. 디스크 삽입 후 키를 누르면 Game Disk A 에서 여러 번 무언가를 로드한 후에 이 화면이 출력되는데, 이 때 print_text 를 비롯한 함수들의 코드도 로드되고 폰트도 VRAM 에 올려지게 된다.
즉 덮어써야 하는 시점은 바로 이 부분이 된다. 여기에서 처음 로드하는 코드 부분을 덮어쓰면 될 것이다. 디버거로 확인해보면 Game Disk A 의 0x2000 오프셋부터 시작하는 코드가 메모리의 0x8000 주소에 로드되는 것을 볼 수 있다. 이 부분을 덮어쓴 다음, 프린세스 메이커 때와 동일하게 코드를 계속 상주시킬 주소에 실제 코드를 복사한 다음 다시 원래대로 복원해서 점프하면 된다. 코드는 대략 아래와 같은 식이다.
INIT:
org 0x8000
push af
push bc
push de
push hl
push ix
push iy
; copy data
ld bc, PROLOGUE - HANGUL_CHO_DATA
ld hl, HANGUL_CHO_DATA
ld de, HANGUL_FONT_CHO
ldir
ld bc, END - START_PERSIST_CODE
ld hl, PROLOGUE
ld de, START_PERSIST_CODE
ldir
; jump to PROLOGUE
jp START_PERSIST_CODE
PROLOGUE:
org START_PERSIST_CODE
ld a, (RAMAD2)
ld hl, $8000
call ENASLT
ei
ld c, $1A
ld de, $8000
call BDOS
ld c, $2F
ld hl, $0800
ld de, $0597
call BDOS
ld a, (RAMAD2)
ld hl, $8000
call ENASLT
ei
pop iy
pop ix
pop hl
pop de
pop bc
pop af
jp START_INIT
이런 식으로, 우선 코드나 폰트 데이터 등을 원하는 주소에 복사한 다음 해당 주소로 점프한 다음 0x8000 주소에는 원래 있었어야 할 코드를 디스크에서 다시 읽어서 로드한다. 물론 이 원래 코드는 디스크의 다른 부분에 미리 복사해두어야 할 것이다. 룬워스의 Game Disk A 에는 여유 공간이 그리 많지는 않지만, 뒤쪽에 0x1000 정도 넣는 것은 문제가 없으므로 0x2000 ~ 0x3000 오프셋에 있는 데이터를 0xB2E00 오프셋에 미리 복사해서 그것을 0x8000 에 다시 로드해서 복원한다.
디스크 읽기는 이번에는 그냥 BDOS 를 직접 호출했다. 에러 핸들링은 귀찮으니 그냥 생략하기로 했다.
그리고 위의 코드에는 없지만, Hook 점프 코드 설정 및 일부 값 수정 루틴도 들어간다. 수정해야 하는 값은 뒤에서 따로 설명한다.
Hook
이제 어디에 Hook 을 걸어야 하는지를 알아보아야 한다. 고유코드를 2bytes 로 확장하기 위해서는 대사 코드 하나를 가져와서 처리를 시작하는 부분에 Hook 을 걸어야한다. 이는 물론 print_text 함수에 있으며 위에 첨부한 이미지를 다시 한 번 보면 아래와 같다.
이보다 위 쪽에도 대사 코드를 가져와서 일부 특수문자를 체크하는 등의 루틴이 있기는 하지만, get_text_one_char 함수는 hl 레지스터를 인자로 받는데 위에서 호출하는 것들은 hl 레지스터를 증가시키지 않으므로 계속 같은 코드를 가져온다. 실제로 inc hl 을 실행하는 루틴은 위 이미지에 나와있는 곳 뿐이다. 따라서 이 부분에서 Hook 을 해야한다.
이전에 서술했듯이 00 ~ 06 의 제어코드를 체크하는데, 어차피 확장하는 영역은 0xAC ~ 0xD7 이므로 제어코드는 그대로 유지되어야 한다. 따라서 실제로 Hook 해야 하는 부분은 오른쪽의 print_font 함수를 호출하는 부분이다.
이 함수에서는 원래 get_text_one_char 가 a 레지스터로 리턴한 대사 코드 1byte 를 그대로 받아서 처리를 하므로, 여기에 Hook 을 걸어서 a 레지스터 값이 0xAC ~ 0xD7 인지 체크하여 만약 아니라면 그냥 그대로 print_font 를 다시 호출하고 돌아오도록 하고, 한글 코드 영역이라면 뒤의 대사 코드 1byte 를 더 받아서 그 때부터 원하는 처리를 하면 될 것이다.
그리고 이를 이용해 한글 폰트를 생성한 다음, 이를 화면에 출력하도록 해야하는데 색상 처리 등으로 인해 출력 루틴까지 굳이 새로 만드는 것은 번거롭기 때문에 기존의 print_font 함수를 거의 그대로 이용하는 방향으로 처리할 수 있다. 다시 한 번 위의 print_font 의 처리 과정을 서술해보면 아래와 같다.
- Page 0 의 (0, 212) 위치부터 8x10 영역을 특정 색상으로 채운다.
Page 2 의 (152, 222) 위치에 있는 8x10 영역을 Page 0 의 (0, 212) 위치로 복사한다.- Page 0 의 (0, 212) 위치부터 8x10 영역을 특정 색상으로 채운다.
- Page 0 의 (0, 212) 위치에 있는 8x10 영역을 Page 2 의 (36, 21) 위치에 복사한다.
여기서 중요한 점은, 실제로 원본 폰트 위치에서 복사하는 것은 2번 뿐이고 나머지는 모두 (0, 212) 라는 미리 지정된 임시 버퍼같은 위치에서 처리한다는 것이다. 이 말은 결국 2번의 LMMM 커맨드에서 폰트를 불러오는 srcX, srcY 좌표만 새로 생성한 한글 폰트 위치로 설정해주면 다른 부분은 전혀 건드릴 필요 없이 동일하다는 것이다.
이 LMMM 커맨드는 print_font 내에서 호출되고, LMMM_SX 와 LMMM_SY 도 print_font 내에서 원래 알고리즘대로 1byte 대사 코드를 기반으로 연산되서 설정된다. 따라서 여기서는 print_font 함수 호출 이전에 Hook 을 걸기 때문에 그냥 함수를 호출해서는 원하는 작업을 할 수가 없다. 따라서 여기서는 print_font 함수의 일부분을 직접 실행한 뒤 중간으로 점프하는 방식으로 구현을 할 것이다.
그리고 한글 폰트 생성을 별 다른 연산 없이 초성 중성 종성 폰트를 그대로 합치는 거였다면 VRAM 에 초/중/종성 폰트를 미리 로드해서 VDP 커맨드만으로 처리할 수 있겠지만 여기서는 휴리스틱 연산으로 인해 그렇게 할 수는 없다. 따라서 이 모든 처리는 CPU 에서 하고, 초/중/종성 폰트 역시 RAM 에 상주하도록 구현했다. RAM 에서 한글 폰트를 구성하고 나면 이 데이터를 HMMC/LMMC 커맨드를 이용해서 VRAM 에 쓰는 방식으로 구현한다.
원래 이러한 단순 복사는 로지컬 연산이 필요없으므로 HMMC 를 사용하면 되지만 실수로 LMMC 로 구현을 해버린 관계로 그대로 사용했다. 어차피 테스트 결과 속도 문제는 없었으므로 별 상관은 없다.
또한 생성한 한글 폰트를 쓰는 VRAM 위치는 적당히 Page 2 의 (96, 222) 위치로 결정했다. 이는 아래의 위치이다.

어느 위치로 해도 상관 없으나, 원래 0xAC 코드의 폰트가 있는 위치로 결정했다. 여기서 하는 작업은 상당히 많고 길기 때문에 코드는 이곳에 첨부하진 않고 Github 를 참조하면 된다. 대신 어떤 작업을 하는지 과정을 간략하게 순서대로 적어보도록 한다.
- 대사 코드가 0xAC ~ 0xD7 인 경우 뒤의 대사 코드 1byte 를 하나 더 받고 hl 을 증가시킨다.
- 받은 한글 2bytes 코드의 초성, 중성, 종성 코드를 각각 분리한다.
- 각 코드에 따라 미리 넣은 한글 자모 폰트를 가져와서 위에서 Python 으로 구현한 휴리스틱으로 모양을 조정한다.
- 조정 후 모두 조합해서 12bytes 의 한글 폰트 하나를 생성한다.
- 생성한 폰트 데이터를 LMMC 커맨드를 이용해 VDP 에 넘겨서 Page 2 의 (96, 222) 위치에 기록한다.
- print_font 의 앞 부분 코드를 일부 대신 실행하여 LMMM_SX 와 LMMM_SY 를 (96, 222) 로 설정한다.
- print_font 의 나머지 뒷 부분 코드로 점프한다.
뒤의 6, 7번만 다시 확인해보면 아래와 같다.
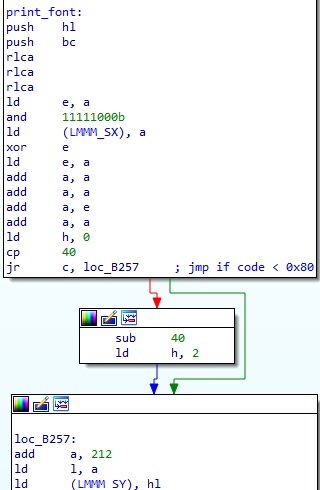
원래 print_font 함수에서 LMMM_SX 와 LMMM_SY 를 설정하는 것은 이 루틴 내에 존재한다. 따라서 이를 핸들러에서 그대로 실행한 다음 점프하는 코드를 만들어보면 아래와 같다.
PRINT_FONT:
ld de, $B090
push de
push hl
push bc
rlca
rlca
rlca
ld e, a
and %11111000
ld a, $60 ; 96
ld (LMMM_SX), a
xor e
ld e, a
add a, a
add a, a
add a, e
add a, a
ld h, $00
cp 40
jr c, loc_B257
sub 40
ld h, $02
loc_B257:
add a, $D4
ld l, a
ld hl, $02DE ; 222
ld (LMMM_SY), hl
jp $B25D
원래 print_font 함수는 call 로 호출되기 때문에, 점프 후 정상적으로 리턴되도록 Return address 를 스택에 직접 넣어주어야 한다. 원래 print_font 함수 호출 바로 뒤의 코드 주소는 0xB090 이므로, 이를 먼저 스택에 push 한다.
이후 코드를 거의 동일하게 실행하고(사실 굳이 그럴 필요는 없지만), LMMM_SX 위치에 96 을 강제로 넣고, 마찬가지로 LMMM_SY 위치에도 222 를 강제로 넣는다. 그리고 실제 print_font 함수에서 LMMM_SY 에 값을 쓴 바로 뒤의 코드 주소인 0xB25D 로 점프한다. 이렇게 하면 이후에는 원래 print_font 함수의 동작대로 실행이 되며 한글이 출력된다.
8x10 → 8x12
위와 같이 패치를 하고 나서, 한글 대사를 간단하게 테스트로 넣고 게임을 실행해보면 아래와 같은 출력을 볼 수 있다.
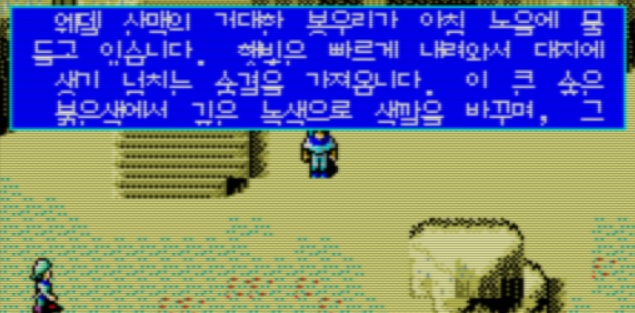
보다시피 아직 그대로 8x10 출력이기 때문에, 한글 아래쪽이 짤린 채로 나오는 것을 볼 수 있다. 이제 이걸 8x12 에 맞게 출력하는 작업을 해야한다. 일단 폰트 크기는 8x10 이지만, 위 이미지를 보다시피 줄마다 2픽셀의 여백이 존재한다. 따라서 일단 대사창 위치에 폰트를 출력할 때는 크기만 8x12 로 변경해주면 겹치지 않고 출력이 될 수는 있다.
그래서 일단 또 다시 print_font 의 출력 과정을, 수정된 버전으로 보면 다음과 같다.
- Page 0 의 (0, 212) 위치부터 8x10 영역을 특정 색상으로 채운다.
- Page 2 의 (96, 222) 위치에 있는 8x10 영역을 Page 0 의 (0, 212) 위치로 복사한다.
- Page 0 의 (0, 212) 위치부터 8x10 영역을 특정 색상으로 채운다.
- Page 0 의 (0, 212) 위치에 있는 8x10 영역을 Page 2 의 (36, 21) 위치에 복사한다.
위의 과정은 모두 VDP 커맨드이므로, VDP 커맨드 레지스터 설정 값만 변경하면 된다. VDP 커맨드 레지스터는 여기에서 확인할 수 있는데 아래와 같은 종류가 있다.
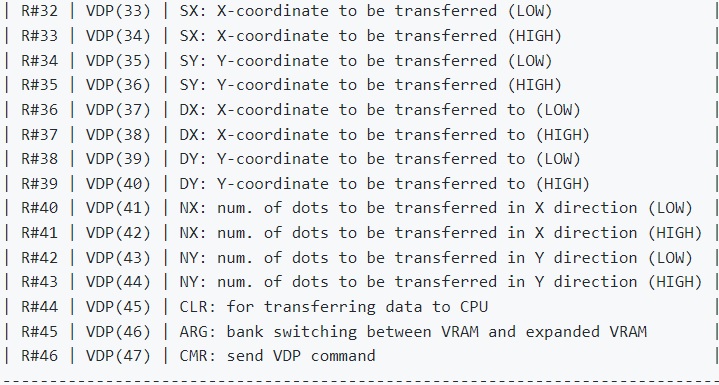
커맨드에 따라 SX SY 는 사용하지 않기도 하지만, 어쨌든 기본적으로 연속적인 레지스터 번호를 가지고 있기 때문에 보통 이를 설정하기 위해 R#17 레지스터를 이용한 간접 레지스터 접근을 하게 된다. 이 간접 접근 방식은 Auto increment 도 있으므로 연속적인 out 명령으로 쓰는 것이 가능하고, 물론 otir 를 사용할 수도 있다. 이 때 레지스터 설정 값도 특정 주소에 연속적으로 배치해놓는다. 따라서 이를 찾아서 수정하면 된다.
우선 이미 print_font 함수에서 LMMM_SX, LMMM_SY 로 봤었던 LMMM 커맨드의 값 위치를 확인해보면 아래와 같다.
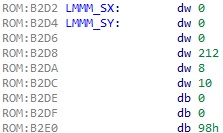
SX 부터 NY 까지는 각각 2bytes 이고, LOW 와 HIGH 값을 보낸다. 위에서는 편의상 그 값들은 dw 로 2bytes 를 표현하도록 했다. 어쨌든 LMMM 커맨드는 SX SY 까지 모두 사용하는데, 실제로 위 레지스터 리스트와 동일하게 2bytes 값 6개와 1byte 값 3개(2*6 + 3 = 15)를 보내는 것을 볼 수 있다. 마지막의 0x98 은 LMMM 커맨드 및 특정 로지컬 연산을 의미한다.
여기서 주목할 것은 물론 NX 와 NY 인 (8, 10) 이다. 여기서 NY 값인 10 을 12 로 수정하면 한글 폰트의 위치에서 8x10 이 아닌 8x12 를 복사하게 된다. 그래서 이 값도 수정을 해야 한다.
이런 식으로 8x10 으로 된 모든 부분을 수정해야 한다. 이를 찾는 건 쉬우니 별 문제가 없다. 그래서 우선 이런 식으로 print_font 에서 사용하는 VDP 커맨드에서 8x10 부분만 전부 8x12 으로 바꿔서 실행해보면 아래와 같은 결과를 얻는다.
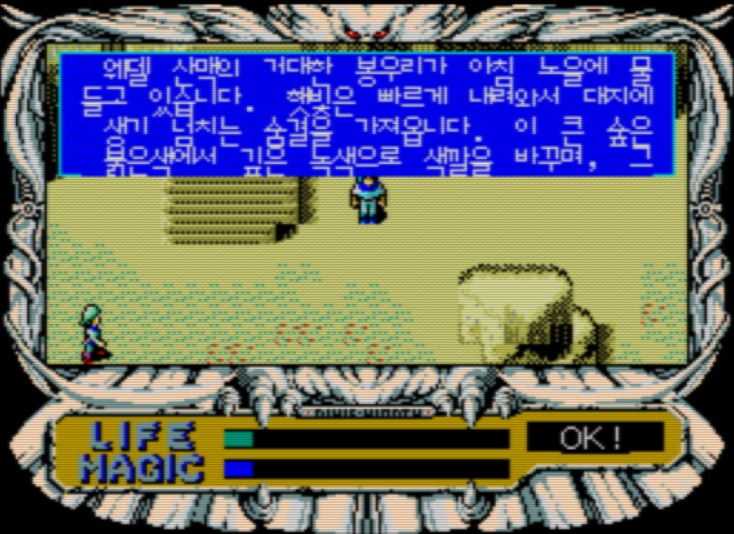
줄 간격이 없어져서 거의 딱 붙었지만 일단 그럴듯하게 출력된다. 그러나 문제는 대사 창 사이즈가 8x10 에 맞춰져있어서 가장 아래쪽 줄을 보면 대사창을 초과해서 덮어써진 것을 볼 수 있다. 그 외에도 아래쪽에 “OK!” 라는 글자를 보면 이것도 약간 초과된 것을 볼 수 있다. 어쨌든 이로 인해 대사가 스크롤되면 더욱 큰 문제가 발생한다.
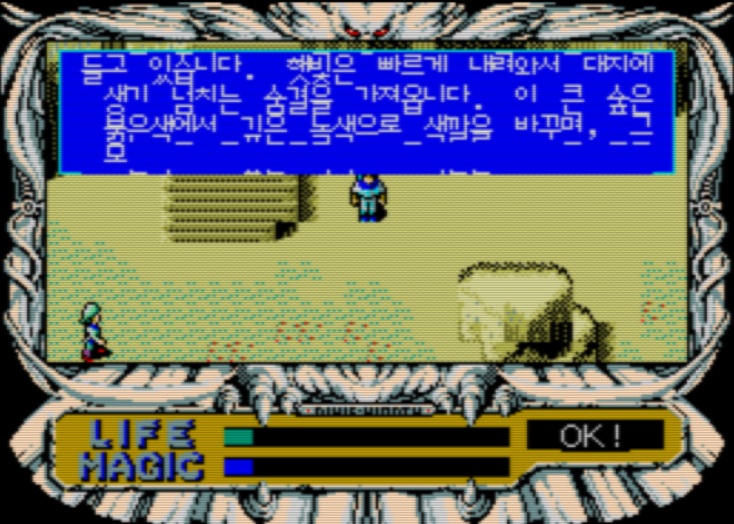
초과된 부분까지 스크롤되면서 복사되어 엉망이 되는 것을 볼 수 있다. 이를 해결해야 하는데 우선 초과되는 것을 수정하기 전에, 문제가 하나 더 보이는데 가장 위쪽 줄에 무언가 남는 것을 볼 수 있다. 이를 먼저 수정해보자. 스크롤은 print_text 함수 내의 아래의 루틴에서 처리한다.
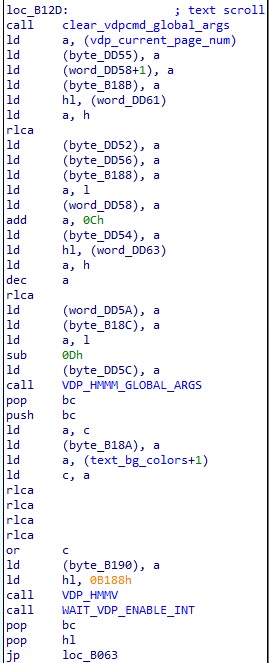
여기서는 print_font 와 달리, 이런저런 연산을 통해서 VDP 레지스터를 설정할 값을 만든다. 따라서 이는 미리 수정하는 것은 번거롭고 Hook 을 걸어서 원하는 VDP 레지스터를 설정하고 다시 점프하도록 만들도록 한다.
스크롤은 아래의 3줄을 가장 위쪽 줄에 복사한 다음, 마지막 줄을 지우는 식으로 진행된다. 여기서 3줄을 복사하는 HMMM 커맨드의 레지스터 설정 값을 디버거로 확인해보면 아래와 같다.

보면 (28, 32) 위치에서 (28, 20) 위치로 206x36 만큼 복사하는 것을 볼 수 있다. 이는 정확히 3줄을 위로 끌어올리는 작업이다. 별 문제가 없어보이지만 이것이 문제가 되는 이유는 아래와 같다.
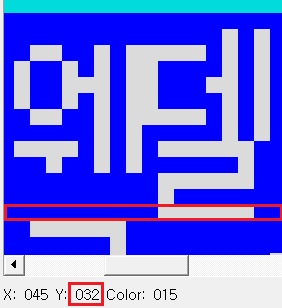
Y 좌표 32 는 첫 번째 줄의 마지막 12번째 줄이다. 따라서 이것까지 같이 복사가 되어버린다. 원래는 폰트가 8x10 이었고 줄 간격 여백이 2픽셀이 있었으므로 위와 같은 동작이 전혀 문제가 되지 않았으나 지금은 8x12 로 변경하면서 여백이 없기 때문에 위처럼 된 것이다. 따라서 이 문제를 해결하려면 (28, 33) 위치에서 (28, 21) 위치로 복사하도록 변경해야 한다. 즉 결과적으로 SY 와 DY 를 변경해야 한다.
그런데 이 루틴에서 쓰는 0xDD58 주소가 DY 이고 0xDD54 주소가 SY 인데, 코드를 보면 DY 에 a 레지스터를 쓰고, 이후 add a, 0Ch 를 한 다음 SY 에 쓰는 것을 볼 수 있다. 따라서 DY 에 쓰기 직전에 Hook 을 해서 a 레지스터를 1 증가시켜주고 다시 돌아오기만 하면 SY 와 DY 가 둘 다 1 증가되어 원하는 대로 (28, 33) 위치에서 (28, 21) 위치로 복사되도록 할 수 있다.
이렇게 Hook 을 해서 처리하도록 하고 테스트를 해보면 아래와 같다.
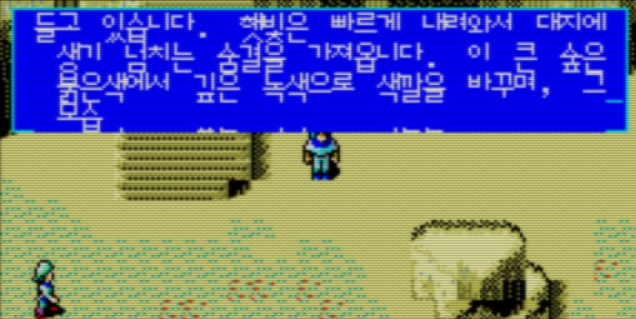
아까의 문제가 해결되었고 덤으로 중간 중간에 한 줄이 더 복사되는 문제도 같이 해결이 되었다. 그런데 밑에 글자의 흔적이 남는 건 여전한데, 이 문제는 스크롤을 하면서 복사 후에 4번째 줄을 지우면서 12 가 아닌 10줄을 지우기 때문에 발생한다. 이는 위의 스크롤 루틴에서 HMMV 커맨드를 호출할 때의 레지스터 설정값이 0xB188 에 있는데, 여기에서 NY 가 10 으로 고정되어 있으므로 이를 12 로 수정해주면 해결된다.
하지만 그럼에도 대사창 크기가 작아서 초과하는 문제는 여전한데, 이는 대사창을 그리는 루틴을 찾아서 대사창 크기 자체를 늘려야 한다. 대사창도 VDP 커맨드를 통해 그리는데, 이러한 단색 그리기는 HMMV 나 LMMV 커맨드를 사용하므로 이를 이용해서 추적할 수 있다.
그러나 이 부분은 짐작할 수 있다시피 저 대사창 뿐 아니라 상당히 많은 부분에서 초과되기 때문에 수정을 많이 해야한다. 따라서 이러한 크기들이 정의되어 있는 부분을 일일이 찾는 것은 상당히 번거롭다. 그래서 이번에는 단순히 Hook 을 걸어서 레지스터 설정 값을 체크해서 대사창 등 원하는 크기나 좌표일 때 각각 원하는 값으로 설정하는 방법을 사용하기로 한다. 물론 이것도 일일이 초과되는 부분을 찾고 디버거에서 설정 값을 확인해서 수정해야 한다.
일단 대사창만 간단히 체크해서 수정해보면 결과는 아래와 같다.
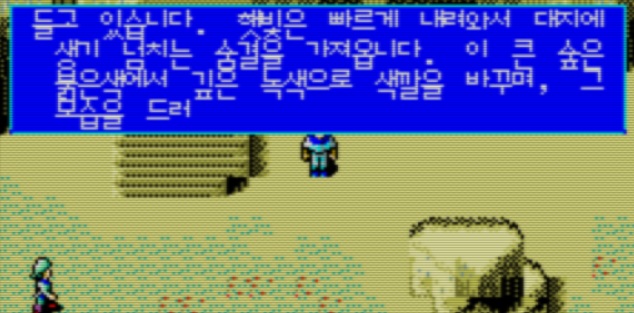
일단 초과되는 것도 없어졌고 문제가 해결되었다. 물론 실제로는 좌우의 세로선 길이도 늘려주어야 하는 등 수정해야 할 것은 몇 개 더 있다. 이런 식으로 초과되는 부분을 수정하는 작업을 동일하게 모두 진행하면 된다.
그리고 폰트를 임시로 쓰는 (0, 212) 위치를 확인해보면 아래와 같다.

8x10 에서 8x12 로 변경했기 때문에, 아래쪽 공간을 침범하는 것을 볼 수 있다. 아래쪽은 그냥 빈 공간이 아니라 공백 폰트이다. 사실 폰트 출력시에 가장 먼저 HMMV 로 지워주는 작업을 하기 때문에 당장 문제가 되지는 않겠으나, 어쨌든 어디서 문제가 발생할지 모르므로 가능하면 이것도 수정해주는 것이 좋을 것이다. 어느 위치로 지정해도 상관없지만, 위의 한글 폰트를 쓰는 위치 (96, 222) 의 바로 오른쪽 위치인 (104, 222) 위치로 결정했다. 이것은 고정이므로 아까 10 을 12 로 수정했던 부분들에 있던 (0, 212) 값들을 일일이 수정해주면 된다.
그리고 이렇게만 해서 끝나는 것은 아니고, 메뉴라든지 여러 부분에서는 텍스트 출력 시작 위치 자체를 변경해야 되는 경우도 있고 그 외에도 다양한 문제들이 발생하므로 모두 다 일일이 찾아서 수정 작업을 해야한다.
어쨌든 이렇게 해서 일단 한글 조합형 폰트 확장이 완료되었다.
Miscellaneous
패치 코드 위치
- 위에서 언급하지 않았는데, 패치 코드 및 한글 자모 폰트의 위치는 0xE000 ~ 0xEF00 정도의 영역으로 결정했다. 이 부분이 게임 내에서 사용되는지 확실하게 체크해보진 않았으나 적당히 진행해보면 별 문제가 발생하지는 않는 듯 보인다. 물론 혹여나 나중에 문제가 생기면 적절히 조정할 수는 있다.
대사 포인터
- 늘 그렇듯이 번역을 하다보면 대사 공간이 부족할 수 있으므로 각 대사의 시작 주소를 변경할 필요가 생기는데, 위에서 print_text 함수 설명에서 대사의 주소를 hl 레지스터로 인자를 받으며 이를 주소에 따라 RAM 또는 VRAM 에서 불러온다고 했었다. 실제로 게임을 시작하고 첫 대사 주소를 설정하는 루틴을 보면 아래와 같다.

- print_text 를 호출하기 전에 hl 레지스터를 0x670A 로 설정해주는 것을 볼 수 있다. 이는 VRAM 에서 불러오는 대사로, 실제 VRAM 상의 대사 주소는 0x1C000 + (0x670A - 0x4000) = 0x1E70A 이다. 이를 수정하려면 이 부분의 hl 레지스터 설정 값을 수정해주면 된다.
- 물론 보다시피 이 경우는 포인터가 어느 한 곳에 모여있는 게 아니라 코드에 포함되어 있으며 각 루틴의 규칙성도 전혀 없다. 따라서 IDA 나 디버거로 일일이 위치를 직접 찾거나 또는 ld hl, nn 명령의 opcode 인 21 nn nn 을 검색하거나 할 수 있다. 물론 대사 주소를 늘 이렇게 설정한다는 보장도 전혀 없고(가령 h 와 l 을 별도로 설정할 수도 있음) hl 레지스터 설정은 당연히 대사 포인터가 아니더라도 많이 사용되는 명령이므로 2개 이상 검색될 수 있는 등 여러가지를 고려해야 한다. 자동화로 모든 포인터를 수집하는 것은 아주 간단하지는 않지만 무리는 없다.
- 이와 별개로, 대사 공간이 거의 반드시 부족할 것으로 추측되는 메뉴나 아이템 등의 문자열은 다행히 포인터가 한 곳에 테이블로 모여있으며 이를 참조하기 때문에 아주 간단하게 한 번에 수정할 수 있다.
추가 작업 계획
- 우선 대사를 모두 덤프한 다음, 번역된 대사만 입력하면 포인터 등 모든 문제를 자동으로 처리하고 바로 패치된 디스크를 만들어주는 전용 툴을 간단하게 만들 계획이다. 이것은 그리 시간이 걸리는 일은 아니지만 귀찮은 작업이라 번역가분을 구해서 본격적으로 작업에 들어가기 전에는 당장 진행하지 않을 수도 있다.
- 룬워스는 주인공 이름을 사용자가 직접 입력할 수 있는데, 아래와 같은 화면이다.
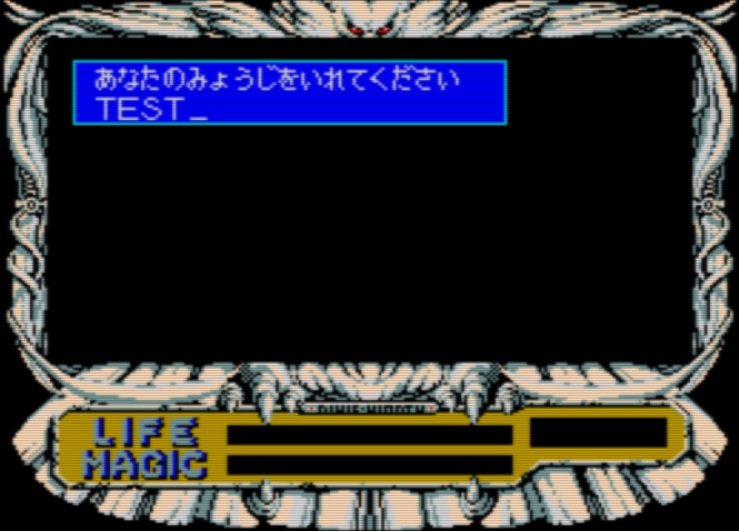
- 고전 콘솔 게임들과 달리, MSX 는 (재믹스같은 예외를 제외하면) 게임기가 아니라 키보드가 있는 컴퓨터이다. 따라서 이름 입력을 할 때 미리 정해진 글자 내에서 직접 선택해서 이름을 입력하는 방식 뿐 아니라, 아예 키보드로 직접 입력하는 방식도 사용할 수 있는데 룬워스가 그런 케이스에 해당한다. 가나 문자 및 알파벳, 특수문자 등을 직접 키보드로 입력할 수 있는데, 이를 한글로 이름 입력을 할 수 있도록 개조할 계획이 있다.
- 이미 현대 한글의 11,172개를 모두 표현하는 조합형 한글을 구현했기 때문에, 한글 입력 구현도 전혀 문제는 없다. 작업은 조만간 시간 나면 할 수도 있고 실제로 번역을 진행하기 시작할 때 할 수도 있다.
Source code
패치 소스 코드는 아래 repository 에 업로드하였다. (sjasmplus 으로 어셈블)
[1] 물론 실행하는 MSX 컴퓨터에 메모리 매퍼가 있다면 설정되어 있는 Segment 그대로 가져온다. 예를 들어서 64KB RAM 컴퓨터에서, 메모리 매퍼의 Page 0 이 Segment 3 으로 설정되어 있고 hl 이 0x2000 라고 가정하면 실제로는 메인 RAM 의 0xE000 주소에서 대사를 가져오는 것이다. ↩