MSX 프린세스 메이커 한글 출력 문제점 보완
by

SeHwa
2022년 10월 18일에 프린세스 메이커 1 의 MSX판 한국어 번역 패치가 공개되었다. 거의 완벽하게 번역되어 공개된 이 패치에는 사소한 문제점 하나가 존재한다고 제작자인 키티야님이 패치 공개와 함께 언급한 바 있다. 나는 공개 직후 이 문제의 원인이 무엇인지 분석하고 해결 방법을 연구해서 어느 정도 패치를 보완하였다. 원래 취미성 작업에 문서화를 거의 하지 않지만 마침 계속 미뤄왔던 블로그를 만들기로 한 김에 첫 포스트로 이번 작업 과정을 정리하기로 했다. 아래에서 이 분석 과정에 대해 상세히 정리해보도록 한다.
Background
게임에 대한 간략한 설명은 아래와 같다.

| 출시 연도 | 1992년 |
| 개발사 | 마이크로 캐빈 |
| 구성 | 디스크 7장 |
| 화면 | SCREEN 7 |
| 최소 요구사양 | MSX2 RAM 64KB VRAM 128KB |
위의 최소 요구사양에 포함시키진 않았지만 중요한 사항으로, 이 게임은 Kanji ROM을 사용해서 텍스트를 출력하기 때문에 실제로 게임을 플레이하려면 Kanji ROM 이 컴퓨터에 내장되어 있거나 또는 외부 슬롯에 Kanji ROM 카트리지를 삽입해야한다. 그렇지 않으면 실행은 되지만 텍스트가 출력되지 않는다.
패치 제작자님이 이 게임을 한국어 번역 패치한 방식은 이 Kanji ROM 내에 있는 한자 영역을 완성형 한글로 덮은 뒤 텍스트 코드를 한글 문장으로 수정하는 방식이다. 이 방식은 ROM 교체가 필요하기 때문에 실제 기기에서는 MMC/SD V4 등의 추가 하드웨어 없이 실행할 수 없다는 단점이 있지만 현재는 에뮬레이터를 이용해 플레이하면 손쉽게 ROM 을 교체할 수 있기 때문에 이는 별 문제가 되지 않는다.
Kanji ROM 은 기본적으로 Shift-JIS 코드를 사용한다. 따라서 대부분의 게임 내 텍스트 코드를 별도로 찾을 필요는 없다. 그러나 이 게임에서는 텍스트 출력에 Kanji ROM 만 사용하는 것이 아니라 별도로 내장된 폰트도 사용한다. 이 점이 후술할 문제가 발생하는 이유 중 하나이다.
한국어 패치 버전을 웹에서 플레이해보려면 아래 버튼을 누르면 된다. (MSX 카페의 파스타님이 제공)
Problem
위 한국어 패치 공개 글에서 제작자님이 밝힌 문제점은 아래와 같다.


위 이미지에서 보다시피 게임상에서 매년 9월 30일에 열리는 수확제에서 캐릭터 이름 텍스트가 제대로 출력되지 않고 깨지는 등의 문제가 발생한다. 이 이름 텍스트 자체는 제작자님이 한글 코드로 수정을 했는데, 이 수정으로 올바르게 나오는 부분은 위의 후보 출력 부분이 아니라 뒤에서 수상자를 발표하는 부분이다.
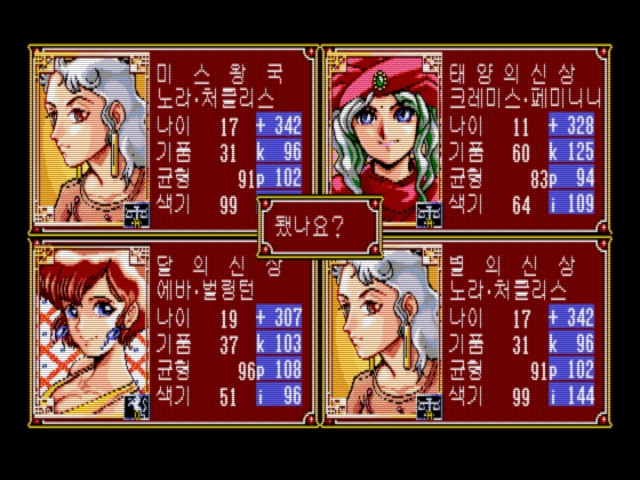
위처럼 수상자 발표 부분에서는 이름이 정상적으로 출력되고 있다. 즉 이름 코드는 하나인데 이를 한글 코드에 맞게 수정하는 순간 앞 부분에서 이름이 모두 깨져서 출력되는 것이다. 이 문제를 해결하기 위해 본격적으로 분석을 해보도록 한다.
Analysis
사용할 분석 도구는 대략 아래와 같다.
| 코드 분석 | IDA Pro |
| 에뮬레이터 | openMSX |
| 디버거 | openMSX-debugger |
우선 가장 먼저 원본 일어판을 실행해서 원래 정상적인 상황에서는 어떻게 출력되는지 확인해보아야 한다.


일어판에서는 양쪽 다 동일한 이름으로 정상적으로 출력된다. 그러나 이름은 동일하지만 출력하는 폰트가 다른 것을 관찰할 수 있다. 뒤에서 출력하는 텍스트는 일반적인 다른 텍스트들과 동일한 16x16 전각 폰트를 사용하고, 이는 Kanji ROM 에서 폰트를 가져와서 출력하는 텍스트이다. 그런데 앞에서 출력하는 텍스트는 대략 8x12 크기의 반각 폰트이면서 가타카나만 확인된다. Kanji ROM 에는 이런 폰트는 없고 Main BIOS 내장 폰트에도 이런 크기는 없으므로 게임 디스크에 내장된 폰트가 확실하고, 디스크에서 폰트 위치를 찾아보면 1번 디스크의 거의 끝 부분에서 아래와 같이 폰트를 찾을 수 있다.

해당 폰트의 저장 패턴은 픽셀당 1bit(1bpp) 로 폰트의 왼쪽 위부터 오른쪽 아래까지 쭉 나열하는 가장 단순한 형태이다. 폰트 크기가 8x12 이므로 한 라인당 1byte 이고, 한 글자가 12bytes 를 차지한다. 이 폰트는 1번 디스크의 0xB1400 부터 0x800 크기만큼 삽입되어 있으며, 단순 계산으로 약 170글자 정도가 저장될 수 있는 공간이다.
이제 다음으로 디스크의 어떤 부분이 어떻게 사용되는지 파악하기 위한 작업을 진행한다. 일단 수확제는 시작하기 전 6번 디스크 삽입을 요구하고 끝나면 다시 다른 디스크를 삽입한다. 따라서 수확제 관련 데이터는 모두 6번 디스크에 있다고 볼 수 있다. 먼저 수확제에서 디스크의 어느 부분을 읽는지 알아보기로 했다. 이를 위해 가장 간단한 방법으로 openMSX 에뮬레이터 코드를 조금 수정하는 방식을 사용하기로 했다.
우선 MSX 에서 디스크 I/O 인터페이스는 Disk-ROM BIOS 에서 노출된다.
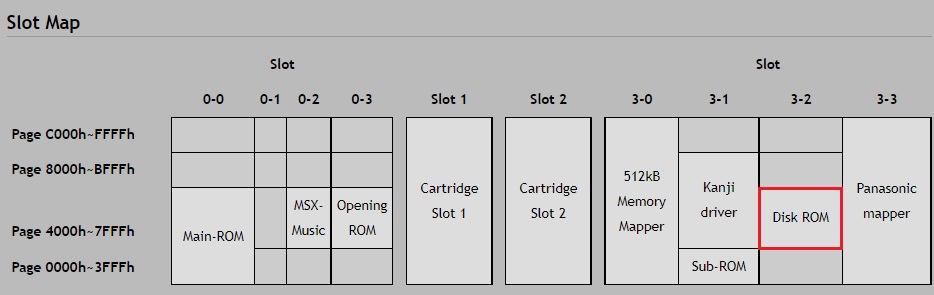 Panasonic FS-A1GT 의 Slot Map
Panasonic FS-A1GT 의 Slot Map
디스크를 읽거나 쓰는 작업은 결과적으로 주소 0x4010 의 DISKIO 기능으로 보통 수렴한다. openMSX 에뮬레이터로 위 이미지의 Slot Map 을 가지는 기기인 FS-A1GT 를 기준으로 Slot 3-2 의 0x4010 위치의 코드를 확인해보면 아래와 같다.
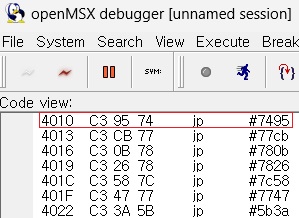
점프 테이블에서 0x4010 위치에는 jp $7495 라는 점프 코드가 있는 것을 확인할 수 있다. 이를 이용해서 openMSX 에뮬레이터의 소스 코드에서 이 명령을 실행하는 것을 감지해서 로그를 남기도록 수정하기로 했다. 먼저 openMSX 에서 Z80 instruction 실행 관련 소스는 src/cpu/CPUCore.cc 에 존재한다. jp nn / JP cc,nn 명령을 실행하는 함수는 포스팅하는 시점 기준으로 3950번째 라인에 있는 jp 함수이다.
template<typename T> template<typename COND> II CPUCore<T>::jp(COND cond) {
unsigned addr = RD_WORD_PC<1>(T::CC_JP_1);
T::setMemPtr(addr);
if (cond(getF())) {
setPC(addr);
T::R800ForcePageBreak();
return {0/*3*/, T::CC_JP_A};
} else {
return {3, T::CC_JP_B};
}
}
이 함수 내에서 현재 PC 가 0x4010 이면서 오퍼랜드 주소값이 0x7495 인 경우를 체크하고 로그를 남기면 된다. 어떤 값을 로그로 남길지는 DISKIO 기능 명세를 확인해서 인자를 확인해보면 되고 그 중 지금 필요한 레지스터는 아래와 같다.
| B | 읽을 섹터 수 |
| DE | 읽을 섹터 시작 번호 |
| HL | 읽은 섹터 데이터를 기록할 메모리 주소 |
위의 레지스터만 기록하면 충분하다. 따라서 이를 바탕으로 코드 패치를 하면 아래와 같다.
template<typename T> template<typename COND> II CPUCore<T>::jp(COND cond) {
unsigned addr = RD_WORD_PC<1>(T::CC_JP_1);
if( PC_.w == 0x4010 && addr == 0x7495 ){
FILE *fp = fopen("log.txt", "a");
fprintf(fp, "B=%02X DE=%02X HL=%02X\n", (BC_.w & 0xFF00) >> 8, DE_.w, HL_.w);
fclose(fp);
}
T::setMemPtr(addr);
if (cond(getF())) {
setPC(addr);
T::R800ForcePageBreak();
return {0/*3*/, T::CC_JP_A};
} else {
return {3, T::CC_JP_B};
}
}
이렇게 해서 openMSX 를 새로 빌드하고 사용하였다. 게임을 시작하고 미스왕국 콘테스트를 선택하고 나서 후보 화면이 출력될때까지 기록되는 로그를 관찰해보면 아래와 같다.
B=0C DE=11 HL=7200
B=03 DE=79 HL=C000
B=01 DE=4B2 HL=BC00
B=04 DE=136 HL=8E00
B=03 DE=2B9 HL=8E00
B=04 DE=2C6 HL=8E00
B=02 DE=2CA HL=8E00
B=05 DE=131 HL=8E00
B=06 DE=C0 HL=8E00
B=06 DE=BA HL=8E00
B=06 DE=87 HL=8E00
B=06 DE=120 HL=8E00
B=06 DE=EA HL=8E00
B=07 DE=FC HL=8E00
B=05 DE=AF HL=8E00
B=06 DE=DF HL=8E00
B=05 DE=115 HL=8E00
B=05 DE=E5 HL=8E00
B=07 DE=49E HL=8E00
콘테스트 오프닝 이미지 및 후보 이미지 등 많은 이미지가 로드되어야 하는 정황상 위에서 로드하는 데이터의 대다수는 이미지 데이터일 가능성이 크다. 일단 위 로드하는 데이터들의 디스크에서의 실제 오프셋을 찾으려면 DE 레지스터(섹터 번호)에 1섹터의 크기(512bytes)를 곱하면 된다. 이 중에서 먼저 0x7200 에 로드하는 데이터는 6번 디스크의 0x11 * 0x200 = 0x2200 위치에 존재한다. 이를 헥스 에디터로 살펴보면 아래와 같다.
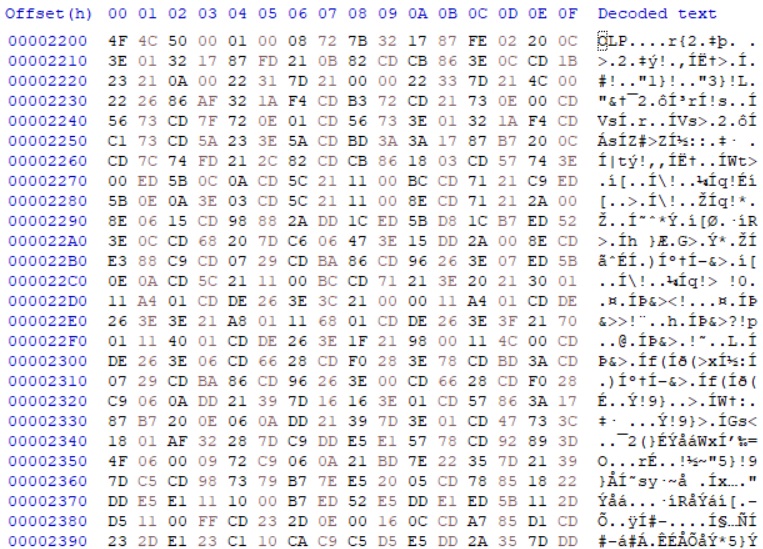
이 데이터는 보기만 해도 Z80 opcodes 라는 것을 쉽게 눈치챌 수 있다. 즉 미스왕국 콘테스트를 선택하고 나면 0x7200 에 콘테스트용 실행 코드를 로드하고 실행한다는 것을 추측할 수 있다. 이는 디버거로 바로 확인할 수 있다. 또한 그와 별개로 이름 텍스트 위치는 Shift-JIS 코드이므로 검색만 해도 바로 찾을 수 있다. 그러나 한국어 패치된 디스크의 경우 Kanji ROM 에 덮어쓴 한글에 대한 코드 테이블을 갖고 있지 않아서 만들기 귀찮으므로, 원본 일어판으로 실행해서 가타카나로 된 일어 이름을 그대로 Shift-JIS 코드로 검색하면 쉽게 찾을 수 있다.
다음으로 위의 0x7200 에 로드하는 코드를 IDA Pro 로 분석하기 위한 설정으로, 사실 원래 몇 년 전부터 MSX 의 메가롬 매퍼 및 디스크 파일 등 주소가 고정적이지 않은 경우의 분석을 좀 더 편하게 해주는 IDA Plugin 을 개발하려고 했는데, 계속 미루면서 결국 지금도 만들지 못하고 있는 관계로 이번에는 그냥 IDA 를 필요할때마다 여러 개 켜서 base address 를 매번 필요에 맞게 설정해서 분석을 했다. 이 경우 6번 디스크의 0x2200 오프셋에 있는 데이터가 메모리 주소 0x7200 에 로드되는 것이므로 base address 를 아래처럼 0x5000 으로 설정하면 된다.
그리고 상술한 대로 IDA 를 여러 개 열어서 분석하는 이유는 아래에서 볼 수 있다.
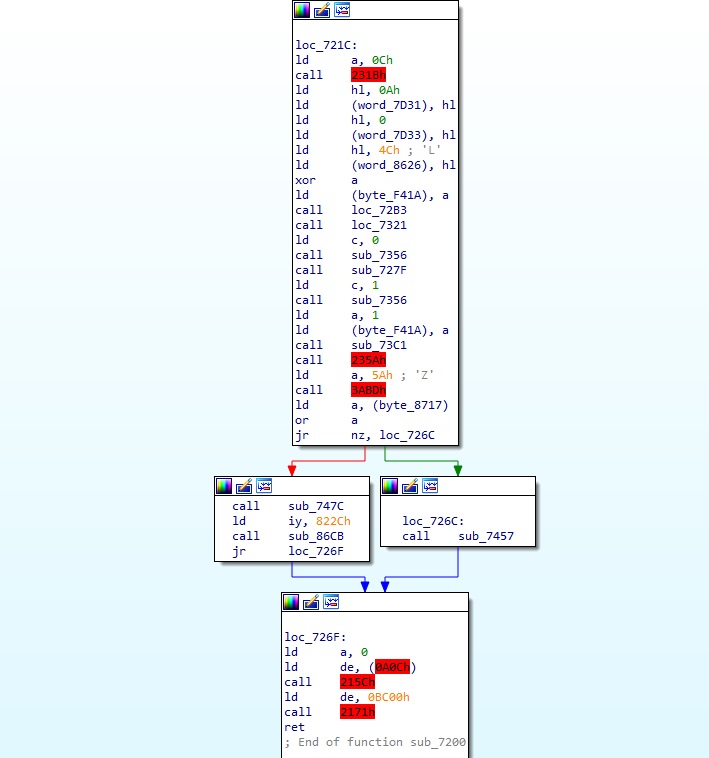
위의 빨간색으로 나오는 부분들은 실제 디버거로 추적해서 해당 코드 데이터를 헥스 에디터로 디스크에서 검색해보면 1번 디스크에 있는 경우가 많다.(물론 BIOS 호출 등은 제외하고) 그래서 저런 함수들은 별도로 1번 디스크 등을 IDA 로 열고 각각 필요한 base address 를 계산해서 설정하고 필요에 따라 각 IDA 를 번갈아가며 참조하면서 분석하면 된다.
여기서부터는 저 작은 폰트의 텍스트 출력과 관련된 루틴들을 모두 찾아서 동작을 분석하기 위해 디버거와 함께 열심히 분석하는 과정이다. 사실 8x12 의 작은 폰트 출력은 수확제만이 아닌 게임 전체에서 사용되기 때문에, 1번 디스크에 존재하고 게임 시작부터 쭉 메모리에 코드가 상주한다. 따라서 대부분은 1번 디스크에 있는 루틴이다. 아래에서 이 루틴들 중 패치와 관련되어 특히 중요한 루틴 몇 가지를 아래에 서술한다.
1. 함수 0x3D76 (1번 디스크 오프셋 0x7976)
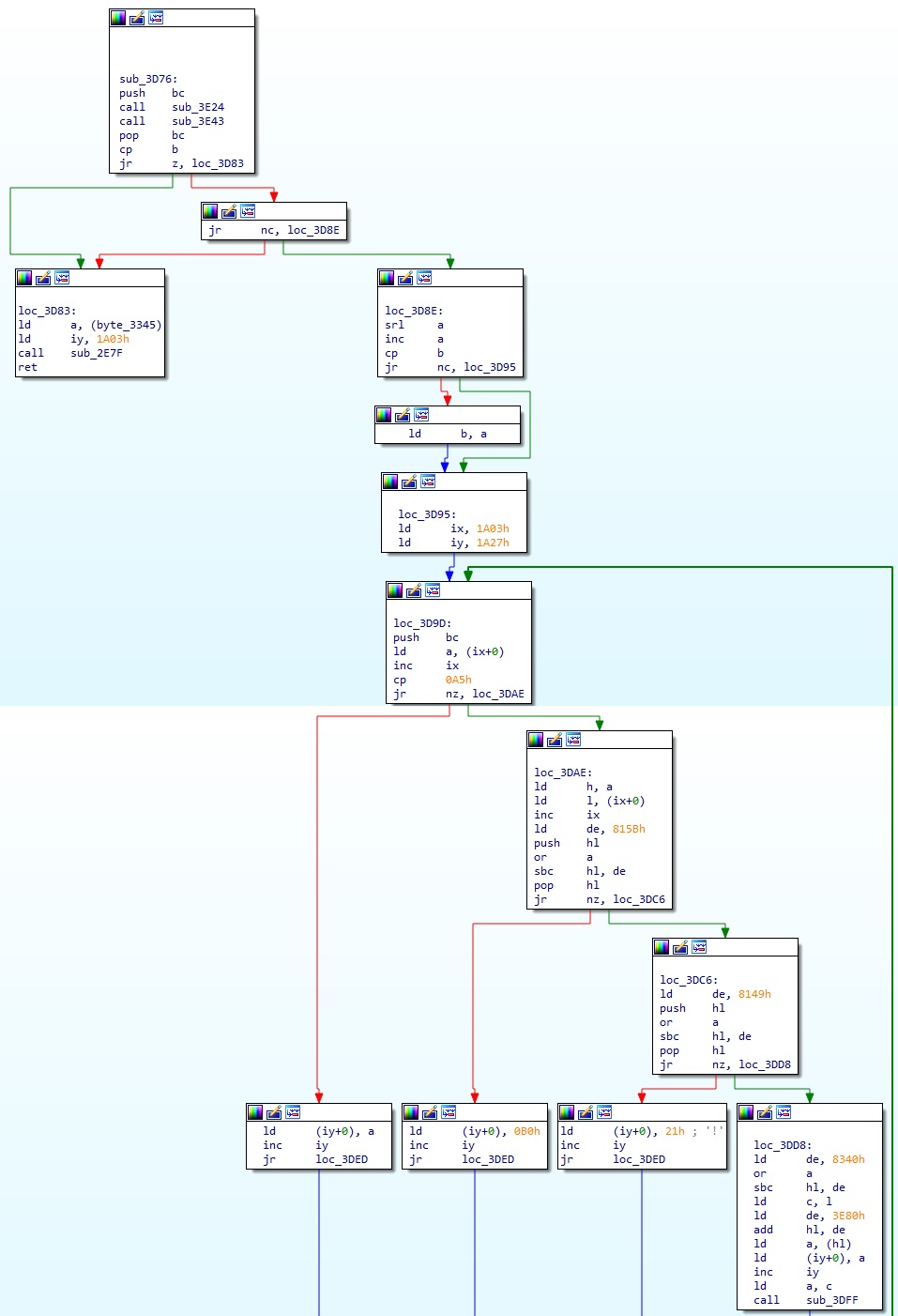
먼저, 프린세스 메이커에서 이름은 family name(성) 과 girl’s name(이름) 으로 나뉘고 모두 가타카나로 이루어진다. 그리고 풀네임을 출력할 때는 · 문자를 사이에 두고 이름과 성을 붙인 문자열을 출력한다. 이 함수에서는 0x1A03 주소에 있는 이름 문자열 데이터를 처리하는데, 이 주소에 있는 이름 문자열이 방금 얘기한 이름과 성을 붙인 전체 문자열이다. 또한 주인공이 아닌 다른 캐릭터의 이름 문자열들은 디스크에 저장된 성과 이름 데이터를 그대로 붙인 것인데, 이 저장된 문자열들은 모두 2bytes 의 Shift-JIS 코드로 되어 있다. 따라서 이름과 성은 가타카나로 이루어지므로 이 문자열은 Shift-JIS 에서 가타카나 영역의 코드만으로 이루어지게 된다.(단 중앙의 · 문자는 0xA5 라는 1byte 코드이므로 예외) Shift-JIS 에서 가타카나 영역은 아래와 같다.

보다시피 전각 가타카나 문자는 대략 0x8340 부터 0x8396 까지의 코드로 이루어진다. 이 경우, 만약 이름이 イイイイ 인 경우 코드는 아래와 같다.
83 43 83 43 83 43 83 43
다시 위 함수로 돌아와서, 함수 코드에서 눈에 띄는 부분을 하나 찾을 수 있는데 loc_3DD8 루틴이다.
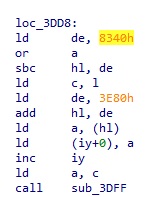
여기서 주목할 수 있는 것은 0x8340 이다. 바로 위에서 Shift-JIS 코드의 가타카나 영역 시작이 0x8340 부터라고 했었다. 이 루틴은 루프문 내에 있고, 여기에 진입할 때 hl 레지스터는 문자열에서 문자 한 글자의 Shift-JIS 코드가 들어있다. 즉, 이 루틴은 Shift-JIS 가타카나로 된 코드에서 0x8340 을 빼서 index 값을 얻는 과정이다. 이 index 값으로 (0x3E80+index) 주소에 접근해서 1byte 값을 가져와서 출력 문자열 주소(0x1A27)에 값을 쓰게된다.
0x3E80 주소에는 아래와 같은 데이터가 있다.
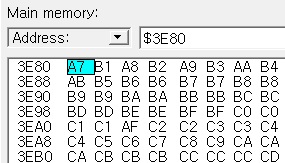
결과적으로 이는 2bytes 로 된 Shift-JIS 가타카나 코드를 각각 순서대로 0x3E80 테이블에 있는 값으로 치환해서 새로운 문자열에 쓰는 것이다. 즉 이름 데이터들은 일단 모두 2bytes 인 전각 가타카나 코드로 저장해놓고, 상황에 따라(전각 문자를 사용하기엔 너무 좁은 영역에 출력하거나 할 때) 이 전각 문자 코드를 그대로 사용해서 Kanji ROM 의 16x16 폰트로 출력하거나 또는 1번 디스크 끝에 내장되어 있던 8x12 크기의 반각 폰트로도 출력할 수 있도록 하는 것이다.
그리고 이 함수 마지막 부분에는 아래와 같은 함수 호출이 있다.
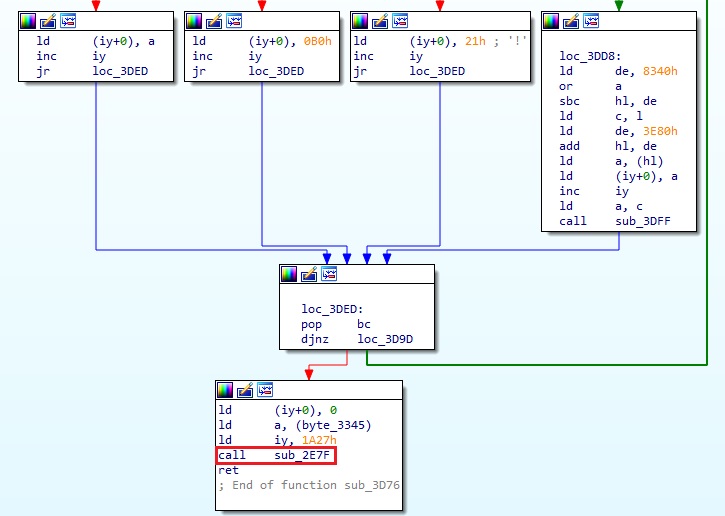
위에서 1byte 코드로 변환한 문자열을 0x1A27 에 다 쓰고 난 다음 0x2E7F 함수를 호출한다. 다음으로는 이 함수를 분석해보도록 한다.
2. 함수 0x2E7F (1번 디스크 오프셋 0x6A7F)
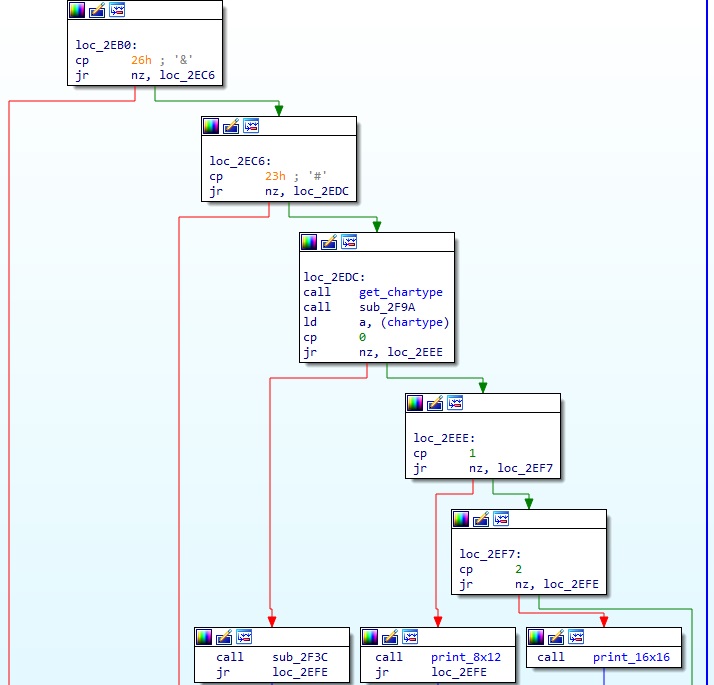
이 함수는 실제로 텍스트를 출력하는 함수이다. 몇 가지 중요한 부분들에 명명을 해놓았는데, 우선 이미지의 루틴은 루프문 내에 있고 앞에서 문자열의 코드 1byte 를 a 레지스터에 넣은 상황이다. 여기서 0x23, 0x26 코드는 별도로 특별히 처리하는지 따로 조건문이 있고, 그 다음으로 get_chartype(0x2F20) 함수가 있다. 이 함수는 문자 코드의 타입을 체크한다. 이 get_chartype 도 매우 중요한 함수이기에 따로 코드를 보면 아래와 같다.
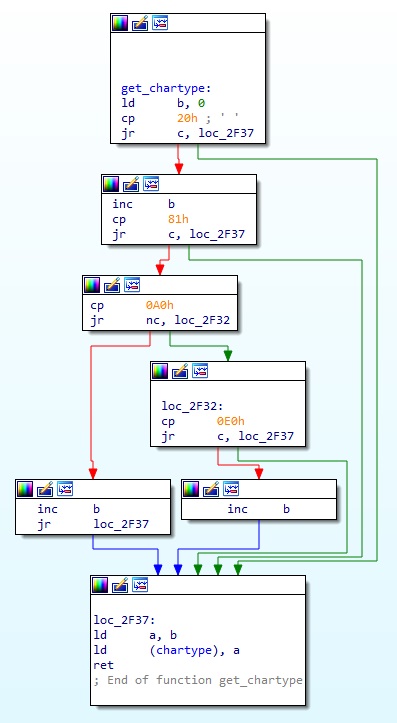
이 함수의 동작을 분석하면, 이 게임의 텍스트 고유코드 영역 전체를 정리할 수 있다.

당연하지만 이 영역은 정확히 Shift-JIS 코드 영역이다. Shift-JIS 영역을 보면 알겠지만 type 1 은 JIS X 0201 영역이고, type 2 는 2bytes 코드 영역(원래 JIS X 0208 한자)이다. 물론 이 type 1 영역의 코드는 모두 디스크에 저장된 내장 폰트를 이용한다. 이 함수에서는 코드의 type 값을 chartype(0x2FF8) 에 넣고 리턴한다.
그리고 다시 0x2E7F 함수로 돌아가서, get_chartype 함수 호출 아래를 보면 얻은 type 으로 조건문을 계산해서 각 type 에 맞는 별도의 루틴을 실행하는 것을 볼 수 있다. 현재 이 글의 목적인 문제점 수정을 위해서는 1byte 코드 출력부만 분석하면 되므로 16x16 폰트 출력 루틴은 굳이 분석할 필요가 없다. 그래서 마지막으로 print_8x12 로 명명한 함수(0x2A2B)를 분석해보기로 한다.
2. 함수 0x2A2B (1번 디스크 오프셋 0x662B)
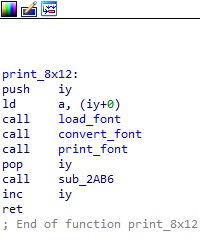
이 함수는 1byte 코드 하나에 대응되는 8x12 폰트를 화면에 출력한다. 내부에서 호출되는 각 함수를 간략하게 설명하면 아래와 같다.
- load_font
– 1byte 코드로 폰트 테이블에서 대응되는 글자의 위치를 찾아서 해당 폰트 데이터를 복사한다. - convert_font
– 디스크에 내장된 폰트 데이터는 단순한 1bpp 데이터지만, 이 게임은 SCREEN 7 을 사용하므로 한 픽셀당 16색 팔레트에서 색을 지정하는 4bpp 이다. 따라서 VRAM 으로 폰트를 전송하기 위해서는 먼저 변환하는 작업이 필요하며 이 함수에서 변환을 진행한다. - print_font
– VDP 에 액세스하여 변환된 픽셀 데이터를 VRAM 으로 전송한다.
위와 같은 과정을 거쳐서 글자 하나가 화면에 출력된다. 여기서 convert_font 와 print_font 는 굳이 건드릴 필요가 없으나, load_font 는 로드하는 폰트의 위치를 결정하는 중요한 함수이므로 문제 해결에 꼭 필요하다. 따라서 이 함수만 별도로 아래에서 코드를 보도록 한다.
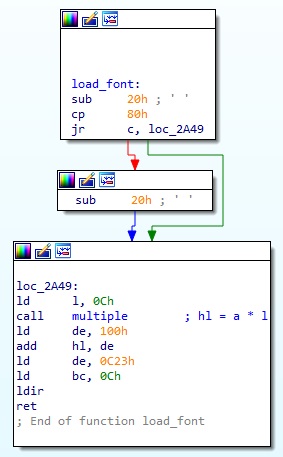
아까 위에서 고유코드 영역을 보면, type 1 코드는 최소 0x20 이고, 0x81 ~ 0xA0 까지 끊겼다가 다시 type 1 코드가 시작된다. 그래서 이 함수에서는 먼저 현재 글자 코드에서 0x20 을 빼고, 뺀 값이 0x80 이상이면 0x20 을 한번 더 뺀다. 여기서는 이미 정상적인 코드가 들어온다고 가정하고 있으므로, 결국 이 코드는 type 1 의 코드를 0x00 부터 연속적인 코드로 정규화하는 것이다.(코드가 0x7F 이면 결과가 0x5F 가 되고, 0xA0 이면 결과가 0x60 이 됨)
그리고 이렇게 연속적이게 만든 결과값을 이용해서 원하는 폰트 위치를 찾는다. 한 글자당 12bytes(0x0C)를 차지하므로 위 값에 12 를 곱하면 정확히 원하는 위치를 얻을 수 있다. 내장 폰트 데이터는 실제로는 메모리의 0x100 주소에 로드되어 있기 때문에, 0x100 + (x * 0x0C) 주소가 바로 원하는 폰트 데이터의 시작 주소가 된다. 이 주소에 있는 데이터를 12bytes 만큼 0x0C23 주소로 복사하는 것이 이 함수의 역할이다.
이렇게 해서 중요 함수들을 모두 분석했다. 이제 남은 것은 이를 이용해서 어떻게 해당 문제점을 해결해야 할지 생각해보는 것이다.
Root cause
이제 공개된 한국어 패치에서 이름 문자열의 8x12 폰트 출력이 깨지는 원인을 알 수 있게 되었다. 핵심은 상술한 0x3D76 함수에서 2bytes 전각 가타카나 코드를 1byte 반각 가타카나 코드로 변환하는 동작과 관련되어 있다. 이 함수는 기본적으로 캐릭터 이름 문자열이 모두 전각 가타카나 영역 코드(0x8340 ~ 8x8396)로 이루어진다는 가정하에 만들어져있다. 따라서 만약 이 영역을 벗어나는 코드를 사용할 경우 1byte 코드 변환용으로 만들어져있는 0x3E80 테이블의 범위를 벗어나서 엉뚱한 값에 접근하게 되는 것이다. 제작자님이 수정한 Kanji ROM 에서 한글은 한자 영역을 덮었기 때문에 가장 작은 코드가 0x889F 부터 시작한다. 결국 0x3D76 함수에 이러한 한글 코드가 들어가게 되면 전혀 의도치않은 임의의 값들로 이루어진 문자열이 생성되어 출력이 깨지게 되는 것이다.
Scenario
위의 분석 내용을 바탕으로, 문제를 해결할 수 있는 방안을 고찰해보도록 한다. 일단 코드 패치는 필수적인데, 어차피 패치를 한다면 현재 1byte 코드 영역에서 기존에 가타카나가 있던 0xA0 ~ 0xDF 영역의 일부를 2bytes 코드로 확장시키는 것도 쉽게 가능하다. 가령 0xB0, 0xB1 만 이용해도 0xB000 ~ 0xB0FF 와 0xB100 ~ 0xB1FF 로 총 512개의 글자를 확보할 수 있다. 그러나 그보다 먼저 생각해야 할 몇 가지 사항이 있다.
- 폰트 데이터 공간
– 이 게임은 최소 요구하는 RAM 용량이 64KB 이다. 그런데 이 게임은 플레이 중에 상시 유지하는 ROM 슬롯 페이지가 없으며 초기화 이후 평소에는 모든 Page 0 ~ Page 4 가 메모리 매퍼 슬롯으로 설정되어 있다. 따라서 만약 RAM 이 64KB 인 기기에서 실행한다면 대부분의 시간 동안 0x0000 ~ 0xFFFF 주소 공간 전체가 곧 RAM 전체를 가리킨다. 이 공간 내에서 폰트 데이터를 추가로 삽입할 영역을 확보해야 한다. Kanji ROM 에서 폰트를 가져온다면 메모리를 차지하지 않으므로 이런 문제가 없으나, 가능하면 Kanji ROM 을 추가로 수정하지 않고 해결하는 것을 지향한다. 따라서 수확제 진행 중 RAM 에서 여유 공간이 어느 정도 되는지 먼저 확인해보아야 한다. 또한 VRAM 의 경우 수확제 동안만이라도 안 쓰는 영역이 있으면 좋겠으나 전체적으로 계속 덮어쓰여지는 부분이 많다. 물론 꼭 필요하다면 코드 패치로 수확제 동안의 VRAM 영역 사용을 최적화해서 확보해볼 수도 있겠으나 매우 번거롭기 때문에 최후의 수단으로만 생각하였다. - 필요한 글자 수
– 이 문제점 수정은 오직 수확제 진행 중에만 작용하고 이후에는 원래대로 복원하는 방향으로 생각하고 있다. 이는 1byte 폰트가 수확제 뿐 아니라 모든 곳에서 사용되기 때문에 가능한 한 기존의 번역 상태를 그대로 유지하기 위해서이다. 따라서 수확제에서 사용되는 모든 1byte 글자를 우선 정리해야 한다. 미스왕국 콘테스트에서는 모든 캐릭터 이름이 1byte 폰트로 출력될 수 있고, 무투회에서는 길이가 일정 이상 긴 이름만 1byte 폰트로 출력된다. 이 이름들을 모아서 중복을 제외한 총 글자 수를 계산해서 어느 정도의 폰트 공간이 필요한지 먼저 확인이 필요하다. - 디스크 읽기 속도
– 롬 카트리지 게임과 달리 디스크는 읽기 속도가 매우 느리다. 만약 텍스트를 출력할때마다 필요한 폰트를 매번 디스크에서 불러오는 방식으로 구현한다면 디스크 데이터를 읽을 최소한의 공간(1섹터 크기 = 0x200)만으로도 완성형 한글 전체를 8x12 폰트로 넣는 것도 아무런 문제가 없다. 그러나 당연히 이렇게 만들었다가는 텍스트 출력 속도가 심각하게 느리다. 비록 수확제에서만 동작한다고 해도 이렇게 플레이 경험을 해치는 방향은 좋지 않으므로 정말 최후의 수단이 아니라면 이 방식은 보류한다.
그래서 결정한 것은, 일단 폰트 공간이 부족하기 때문에 2bytes 로 확장하지는 않고 1byte 코드만 사용하기로 했다. 내장 폰트의 가타카나 영역을 한글 폰트로 임시로 덮고, 그것만으로는 부족하므로 추가적인 여유 공간에 나머지 폰트 데이터를 올려서 로드하는 방식을 사용하기로 했다. 이는 어디까지나 이 작업이 게임 전체가 아닌 수확제 동안의 이름 문자열만을 한글로 출력하면 되기 때문에 가능한 것이다.
우선 메모리의 여유 공간을 조사하기 위해, 에뮬레이터에서 여러 기기들과 환경으로 설정하고 게임 내에서 다양한 동작을 하며 고정적으로 쓰이지 않는 공간을 조사했다. 사실 굳이 아예 쓰이지 않는 공간이 아니더라도, 수확제 동안에만 사용되지 않는 영역이기만 하면 해당 영역의 데이터를 미리 6번 디스크의 빈 공간(6번 디스크는 뒤쪽에 빈 섹터가 많음)에 미리 복사해둔 다음 필요한 데이터를 쓰고 나중에 수확제가 끝날 때 해당 부분을 디스크에서 읽어서 원래대로 복구만 해주는 방식이면 얼마든지 사용할 수 있다. 수확제 동안 전체 주소 공간이 다 쓰일 가능성은 없으므로 이 방식이면 꽤 많은 메모리를 확보할 수 있다.
다행히 아예 쓰이지 않는 것으로 추측되는 영역들이 적당히 있어서, 위와 같은 디스크 백업 방식은 굳이 사용하지 않아도 될 것으로 보인다. 다만 이 영역들을 덮어도 정말 문제가 안 생길지 완벽한 테스트는 하지 못했기 때문에 장담할 수는 없으며, 이 영역이 그리 크지 않기 때문에 만약 글자가 더 필요하게 되면 다른 방법을 사용해야 한다. 일단 그렇게 조사한 영역에 각각 사용할 용도를 적당히 설정해주었으며 아래와 같다. (0x580 은 여유 공간이 아니라 덮어쓰는 곳)
| 0x580 | 0x200 | 한글 폰트 영역 (1) | 원본 가타카나 폰트 영역에 덮어씀 |
| 0xEA60 | 0x300 | 한글 폰트 영역 (2) | 영역 (1) 에 이어서 넣을 한글 폰트 |
| 0xE700 | 0x170 | 후킹 코드 영역 | 점프 코드 패치로 후킹해서 실행할 핸들러 루틴 |
| 0xCAC0 | 0x100 | 코드 변환 테이블 영역 | 원본 0x3E80 대신 사용할 전각 -> 반각 코드 변환 테이블 |
총합 0x500 크기의 한글 폰트 영역을 확보할 수 있는데, 이론적으로 약 106개의 글자 폰트를 삽입할 수 있다.(실제로는 약간 더 적다) 미스왕국 콘테스트에서만 사용되는 글자가 64개 정도인데 나머지 40개 가량으로 무투회까지 커버할 수 있다면 일단 별 문제가 없을 것으로 생각된다.
그러면 이제 가장 중요한 단계인, 코드 패치를 어떻게 해야할지 구상할 차례이다. 기본적으로 위에 서술한 함수 분석 내용에서 벗어나는 것은 없고, 저 내용에 나온 일부 함수들만 후킹해도 충분히 원하는 목적을 달성할 수 있다. 아래에서 간략하게 정리한다.
1. get_chartype(0x2F20)
이 함수는 코드값으로 1byte / 2bytes 코드 여부를 구분해서 타입을 리턴하는 함수였다. 다시 한 번 원래의 전체 고유코드 영역을 참조해보자.
문제 해결을 위해서는 일단 어떤 식으로든 이 영역을 조정해야 한다. 우선 핵심은 2bytes 코드 영역을 최대한 줄이고 1byte 코드 영역을 늘리는 것이다. 먼저 수정된 Kanji ROM 에서, 한글이 차지하는 영역은 Shift-JIS 에서 한자의 시작 주소인 0x889F 부터 0x94FC 까지임을 확인할 수 있다. 즉, 실제로 필요한 2bytes 코드 영역은 0x88 ~ 0x94 까지이다. 이 말은 곧 0x95 ~ 0xFF 까지를 1byte 코드 영역으로 해도 별 문제가 없다는 것이다.(물론 수확제 쪽을 다 번역해서 한자는 출력하지 않아야 한다) 이렇게 하면 1byte 코드 영역을 좀 더 확보할 수 있다. 0x95 ~ 0xFF 는 107개 정도이며, 위에서 확보한 한글 폰트 영역과 거의 비슷한 수의 글자이다.
정리하면 이 함수를 패치해서, 아래와 같은 범위 체크를 하도록 만든다.

위에서 보다시피 더 확보할 수 있는 영역이 있지만, 일단 100개의 글자로 충분하다면 굳이 이 영역까지는 사용을 하지 않기로 했다. 만약 약간 부족할 경우 공간을 좀 더 확보하는 데에는 별 문제가 없다.
이 함수는 다른 함수들과 다르게, 위에 서술한 대로 동작하도록 하는 데에 매우 간단한 패치만을 요하기 때문에 굳이 후킹을 할 필요가 없고 그냥 원본 코드에서 딱 2bytes 만 변조해도 충분하다.
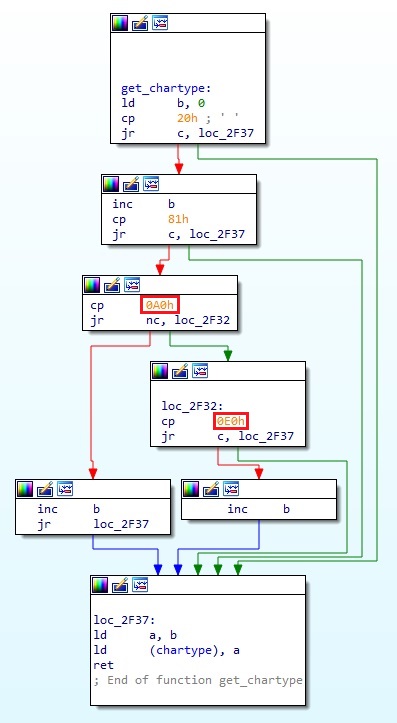
위에서 강조한 두 부분의 값을 원하는 범위대로 각각 0x95, 0xFF 로 수정하기만 하면 간단히 패치가 끝난다.
2. convert_code(0x3D76)
이 함수는 2bytes 전각 가타카나 코드로 이루어진 문자열을 변환 테이블을 이용해서 1byte 반각 가타카나 코드로 이루어진 문자열로 변환하는 함수였다. 원하는 목적을 달성하기 위해서는 이 함수가 2bytes 한글 코드(원래는 Shift-JIS 한자 영역의 코드)로 이루어진 문자열을 받아서 그에 대응되는 1byte 코드로 이루어진 문자열을 출력하는 동작을 하도록 만들어야한다.
그러나 가장 먼저 떠올릴 수 있는 문제점이 있는데, 원본 함수의 동작은 어디까지나 Shift-JIS 가타카나 영역의 코드가 연속적이라는 가정으로 만들어진 것이다. 가타카나는 몇 개 되지 않기 때문에 문제가 되지 않으나, 100개 전후의 글자만 1byte 코드로 변환해야 하는 이 시점에서는 2,000개가 넘는 한글 완성형 코드 전체를 대응시키는 것은 당연히 불가능하다. 따라서 변환해야 하는 2bytes 코드가 연속적이지 않다.
그래서 조금 다른 알고리즘이 필요하다. 위에서 0xCAC0 영역에 새로운 코드 변환 테이블을 만들겠다고 했는데, 여기에 만들 테이블은 원본 테이블처럼 대응되는 1byte 반각 코드가 들어있는 테이블이 아니라, 수확제에서 사용할 한글 글자들의 2bytes 코드들로 이루어진 테이블이다. 이 테이블의 index 가 곧 변환할 1byte 코드가 된다. 예시를 들어보자.
8976=그
8a49=나
8a8b=노
8acd=니
8ad7=다
위는 미스왕국 콘테스트에서 이름으로 사용되는 글자들을 오름차순 정렬해서 5글자만 가져온 것이다. 이제 이 코드들로 테이블을 구성하면 아래와 같다. (편의상 엔디안은 무시)
89 76 8a 49 8a 8b 8a cd 8a d7
이렇게 10bytes 의 테이블을 만들 수 있다. 이제 만약 함수에 8a cd 코드가 들어왔다고 가정하면, 위 테이블의 시작부터 8a cd 가 나올때까지 쭉 루프를 돌며 검색을 한다. 검색 시작 전에 적당한 레지스터 하나를 0 부터 시작해서 1 씩 증가해가며 검색하고, 코드를 찾으면 루프에서 빠져나온다. 이렇게 해서 테이블에 대상 코드가 위치한 index 를 얻게 되고, 이 값을 1byte 코드로 사용해서 변환하는 것이다. 8a cd 인 경우 03 이 되는 것이다. 테이블 크기가 작기 때문에 굳이 이분 검색 등이 필요가 없고 순차 검색으로도 충분하다.
물론 이 index 를 바로 그대로 1byte 코드로 사용하는 것은 아니며, 상술한 get_chartype 함수 패치에서 서술한 범위에 맞게 적당한 base 값을 더해주고 몇 가지 예외를 만드는 등의 처리가 필요하다.(· 문자와 관련된 예외 등 몇 가지가 있는데, 자세한 설명은 생략한다)
패치를 위해서는, 0x3D76 함수의 시작 부분이 아니라 함수의 루프 내에서 실행되는 0x3DD8 루틴을 후킹한다. 따라서 0x3DD8 주소에 점프 코드를 넣는 패치를 하여 별도로 작성할 후킹 핸들러로 점프하도록 하여 핸들러 내에서 위에 서술한 알고리즘을 수행하고 다시 돌아오게 된다. 점프할 핸들러 코드는 대략 아래처럼 작성했다.
HOOK_3DD8:
ld a, $FF
ld de, hl
push ix
ld ix, $CAC0 ; 코드 변환 테이블 주소
LOOP_3DD8:
inc a
ld h, (ix)
ld l, (ix+1)
inc ix
inc ix
sub hl, de
jr c, LOOP_3DD8
add a, $95
ld (iy), a
inc iy
pop ix
jp $3DED
3. load_font(0x2A41)
이 함수는 1byte 코드를 이용해서 폰트 데이터 영역에서 원하는 폰트를 찾아서 복사하는 함수였다. 상술했듯이 원래의 1byte 폰트 영역에서 알파벳과 숫자, 특수문자를 제외한 가타카나 영역은 몇 글자 안 되기 때문에 추가 폰트 영역을 구성했다. 따라서 이 함수를 패치해서 1byte 코드 영역에 따라 기존의 폰트 영역에서 로드할지, 아니면 새로운 폰트 영역에서 로드할지를 결정하는 루틴을 추가해야한다. 이는 특별할 것 없이 간단하다. 만든 코드는 아래와 같다.
HOOK_2A41:
cp $80
jp c, $2A47
cp $BF
jr nc, FONT_NEW
sub $15
jp $2A47
FONT_NEW:
sub $BF
ld l, $0C
call $2068 ; hl = a * l
ld de, $EA60 ; 한글 폰트 영역 (2)
add hl, de
ld de, $0C23
ld bc, $0C
ldir
ret
4. Prologue
이것은 코드 패치는 아니고, 코드 패치를 하기 위한 초기화 작업에 대해 서술한다. 기본적으로 이 모든 작업의 시작은 0x7200 주소에서 시작한다. 이는 수확제에서 무투회 및 미스왕국 콘테스트, 휴식 등을 선택했을 때 디스크에서 코드를 로드하는 주소이다. 위에서 미스왕국 콘테스트의 코드는 6번 디스크의 0x2200 오프셋에서 로드한다고 서술했었다. 따라서 이 패치 작업은 이 0x2200 오프셋에 초기화 코드를 덮어쓰는 것으로 시작한다. 물론, 원본 코드는 백업을 해야 한다. 백업은 6번 디스크의 뒤에 남는 공간이 많으므로 적당한 위치에 원본 코드를 백업하면 된다.
초기화 코드에서 해야할 일은 아래와 같다.
- 한글 폰트 데이터 로드
- 후킹 핸들러 코드 로드
- 1byte 코드 변환용 테이블 로드
- 점프 코드 패치
- 복사한 후킹 핸들러 코드의 Prologue 로 점프
로드할 데이터를 모두 맞는 위치에 로드하고, 상술한 후킹할 루틴들에 점프 코드 패치를 하여 복사해놓은 후킹 핸들러 코드들로 점프하도록 한다. 초기화 작업이 끝나면 후킹 핸들러 루틴에서 Prologue 라고 부르는 특수한 루틴으로 점프한다.
이 Prologue 루틴에서는 위에서 0x2200 오프셋에 있던 원본 코드를 6번 디스크의 백업한 위치에서 읽어서 0x7200 주소에 기록한다. 이 Prologue 루틴은 이미 아까 0x7200 쪽에서 점프해서 0xE700 쪽에 있기 때문에 아무 문제가 없다. 그 다음 0x7200 코드의 Entrypoint 인 0x7208 로 점프하면 원래 진행되어야 할 미스왕국 콘테스트 코드가 실행되며 초기화 작업이 종료된다.
위의 작업은 무투회에도 동일하며, 단지 백업하고 덮어씌울 코드의 오프셋(무투회는 6번 디스크의 0x3A00)만 바뀔 뿐이다. 이것만 변경한 상태로 똑같이 무투회 쪽 코드에도 덮어씌우면 된다. 사실, 이렇게 하는 것보다 수확제 진입 직전에 초기화 코드를 삽입하면 공통적으로 한 번만 실행하면 되니 더 편하고 좋을테지만 이미 이렇게 만들어버린 관계로 바꾸기 귀찮아서 생략하였다.
5. Epilogue
이것은 수확제가 끝난 뒤에 모두 원래 상태로 돌려주는 과정이다. 이를 위해서 수확제가 종료할 때 호출되는 적당한 루틴에 코드 패치를 해주어야 하는데, 여기서는 0x71A9 주소의 코드로 결정했다. 이 부분에도 점프 코드 패치를 해주어 Epilogue 루틴으로 점프하도록 해야한다. 루틴의 동작은 특별할 것 없이 말 그대로 덮어 쓴 데이터를 다시 복원하고 점프 코드 패치도 원래대로 복원하는 과정이다. 덮어 쓴 데이터가 아닌 빈 공간(으로 추정되는 곳)에 로드한 데이터들은 굳이 00 등의 값으로 초기화를 해줄 필요가 없을 듯 하여 그대로 놔두기로 했다.
Miscellaneous
디스크 읽기
- 위에서 디스크 읽기를 로깅하는 데에 사용한 함수는 Disk-ROM BIOS 의 DISKIO(0x4010) 였다. 그러나 이 함수는 사용자 레벨에서 이를 직접 호출하도록 의도된 것이 아니다. 따라서 실제로는 대부분 BDOS 를 통해 호출하게 된다. 이를 직접 호출해도 되지만, 이 게임에 더 상위의 디스크 읽기 함수 래퍼가 구현된 게 있다면 그걸 호출하는 게 가장 좋을 것이다. 디버거로 DISKIO 부터 시작해서 콜스택을 추적하면 디스크 읽기를 위한 최초 호출 함수인 $2171 를 찾을 수 있다. 이 함수는 아래와 같이 사용할 수 있다.
| 인자 | 설명 |
| $2311 주소 변수 | 읽을 섹터 시작 번호 |
| $2313 주소 변수 | 읽을 섹터 수 |
| DE 레지스터 | 읽은 섹터 데이터를 기록할 메모리 주소 |
- 실제로 수확제 시작 시 초기화 코드에서 이를 사용해서 디스크를 읽는 루틴을 보면 아래와 같다.
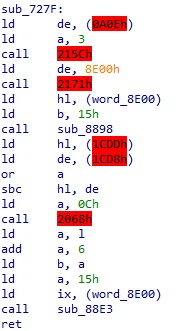
- 사실 위 루틴에도 나와있지만 정확히는 $2311 과 $2313 주소 변수 설정은 $215C 함수를 호출하고 그 내부에서 하게 되는데, 물론 굳이 이것까지 똑같이 할 필요는 없으므로 $215C 함수를 호출할 필요 없이 직접 설정하면 된다.
주인공 이름 출력
- 이 패치로 인해 발생하는 유일한 문제점은 주인공 이름 출력이다. 현재 게임 시작 때 주인공 이름을 짓는 부분은 한글이 아닌 가타카나로 입력하는데, 이 패치는 반각 가타카나 폰트 영역을 덮어버리기 때문에 가타카나를 출력할 수가 없다. 여기에 추가로 convert_code 루틴의 알고리즘을 변경했기 때문에, 원래의 전각 가타카나 코드가 입력으로 들어가면 테이블의 첫 글자(위의 예시를 기준으로 “그”)만 출력된다. 따라서 이 문제를 해결하기 위해서 2가지 방법을 생각해볼 수 있다.
- 주인공 이름이 출력되기 직전의 루틴을 찾아서 점프 코드 패치를 하고, 핸들러에서 원본 가타카나 폰트를 다시 복원하고 다른 점프 코드 패치들도 원래 코드로 복원한다. 그리고 출력이 끝난 직후의 루틴에서도 마찬가지로 코드 패치로 다시 원래의 패치 상태로 돌린다. 이 경우 주인공 이름만 원래의 가타카나로 출력되게 된다. 다만 가타카나 폰트 복원 및 직후의 한글 폰트를 다시 로드하는 데에 디스크 읽기가 필요하다는 단점이 있다. 일단 이 정도 디스크 읽기는 영향을 크게 주는 것은 아니므로 충분히 고려해볼 수 있다.
- 게임 시작 시의 이름을 짓는 부분을 패치해서 가타카나가 아니라 최종적으로 사용될 1byte 한글 글자 중에서 적당한 48글자를 선정해서 해당 글자로 명명할 수 있도록 한다. 이렇게 할 경우 수확제 부분에서 별도의 패치가 필요하지는 않으나, 문제는 주인공 이름은 게임 내내 출력되고 그 중에선 반각으로 출력되는 부분도 있을 수 있기 때문에 결국 이 패치를 수확제 부분이 아닌 게임 전체에 적용해야 한다는 문제가 있다. 또한 이름 명명하는 부분의 패치도 그리 간단하지는 않을 것이므로 상당한 시간이 필요할 수 있다.
- 주인공 이름이 출력되기 직전의 루틴을 찾아서 점프 코드 패치를 하고, 핸들러에서 원본 가타카나 폰트를 다시 복원하고 다른 점프 코드 패치들도 원래 코드로 복원한다. 그리고 출력이 끝난 직후의 루틴에서도 마찬가지로 코드 패치로 다시 원래의 패치 상태로 돌린다. 이 경우 주인공 이름만 원래의 가타카나로 출력되게 된다. 다만 가타카나 폰트 복원 및 직후의 한글 폰트를 다시 로드하는 데에 디스크 읽기가 필요하다는 단점이 있다. 일단 이 정도 디스크 읽기는 영향을 크게 주는 것은 아니므로 충분히 고려해볼 수 있다.
- 그나마 가장 이상적인 방법은 사실 2번이겠으나, 이는 상대적으로 시간도 많이 들고 수확제 외에 게임의 모든 부분을 테스트해야 한다는 단점이 있다. 그래서 1번의 방법을 사용하는 방향으로 고려하고 있다. 이는 현재는 적용하지 않았고 이후 최종 작업을 진행할 때 같이 진행할 예정이다.
Result
 8x12 조합형 폰트
8x12 조합형 폰트
원래 이 게임에서 사용하는 반각 문자 크기는 8x12 이면서 상하 여백이 1라인씩 존재하므로 실제 출력되는 크기는 8x10 이다. 물론 여백이 없는 8x12 폰트를 넣어도 상관은 없으므로 먼저 구글링으로 찾은 이 블로그에서 제공하는 8x12 크기의 조합형 폰트를 삽입해보았다. 위 이미지와 같이 이름이 한글로 잘 출력되는 것을 확인할 수 있다.
추가로 다른 폰트를 더 넣어보기로 하고, 적당한 폰트를 찾다가 달무리 폰트를 찾아서 이를 적당히 8x10 크기에 최대한 맞게 조정해서 1bpp 데이터로 변환하고 넣어보았다.
 달무리 폰트
달무리 폰트
아무래도 트루타입 폰트를 억지로 변환하는 방식으로는 자형이 깔끔하게 나오기 어렵고 8x10 이라는 비율을 맞추면 더욱 이상해져서 가독성이 심히 안 좋지만, 일단 이런 식으로 들어간다는 것을 확인할 수는 있다.
그리고 다른 작업을 위해 폰트를 찾다가, 옛날 16년 전 쯤에 포켓몬스터 한국어화 관련해서 다운받아서 저장해놨던 친9체 폰트를 찾았다. 그림자가 있는 4bpp 폰트 파일이어서 우선 1bpp 로 바꾸고 8x12 크기로 적절히 조정해서 삽입해보았다.
 친9체 폰트
친9체 폰트
약간 직결식 글꼴과 유사한 형태인데, 그래도 이 정도면 위 3가지 폰트 중에서 가독성 면에서는 가장 괜찮고 크기도 그럭저럭 적절한 듯 하다. 어떤 폰트가 더 좋은지는 개인차가 있겠지만 일단 여기까지는 모두 테스트였고 최종 작업물에 어떤 폰트를 사용할지는 아직 결정되지 않았다.
패치 소스 코드는 아래 repository 에 업로드하였다. (sjasmplus 으로 어셈블)