코드 에뮬레이션으로 분석 없이 압축 해제
by

SeHwa
고전 게임 한국어화를 시도하는 사람들이 까다롭게 생각하는 부분 중 대표적인 것으로 압축(무손실 압축)이 있다. 사실 당연하지만 게임 개발사에서 압축 알고리즘을 새로 개발하지는 않기 때문에, 결국 대부분의 압축은 LZ 계열과 허프만의 응용이다. 단지 데이터를 저장하는 형태라든지, Window Size 등의 압축과 관련된 값에서나 차이가 있을 뿐이다. 그러나 어찌됐든 비록 압축 알고리즘 자체는 잘 알려져있다고 해도, 가령 Zlib처럼 특정 라이브러리의 압축 포맷이라면 아무도 압축 해제에 문제를 겪지 않겠지만 게임에서 자체적으로 해당 압축 알고리즘을 구현한 것은 정형화된 포맷이 있는 것은 아니므로 직접 코딩을 해야 하는 경우가 많고, 이 단계에서 포기할 수 있다. 간혹 특정 콘솔 게임기는 SDK 에서 압축 함수를 지원해서, 해당 콘솔의 게임들이 정형화된 압축 포맷을 가지는 경우가 있긴 하지만 여기서 언급하는 것은 그 외의 것들이다.
사실 압축된 데이터를 사용하는 게임은 당연히 게임 코드 내에 압축 해제 루틴이 존재하기 때문에, 코드를 역분석하면 반드시 압축 해제 코드를 만들 수 있다. 또는 비교적 간단한 포맷이면 대강 눈으로 보고 짐작해서 구현할 수도 있다. 하지만 경우에 따라서는 이런 게 상당히 귀찮은 작업이 될 수 있고 사람에 따라서 이 작업에 어려움을 느낄 수도 있기 때문에, 여기서는 게임 내의 압축 해제 코드를 분석하지 않고 압축을 해제하는 방법에 대해 서술해본다.
Background
제목에서 보다시피, 이번에 사용할 방법은 코드 에뮬레이션을 통해 압축을 해제하는 것이다. 사실 흔하게 생각해낼 수 있는 방법이고, 나도 CTF 라든지 본업과 관련된 작업을 할 때 옛날부터 많이 사용한 방법이다. (물론 그 때는 압축과는 관계 없지만) 다만 한국어화 작업에 사용한 것은 이번이 처음이다.
지금까지 한국어화 작업에 사용하지 않은 이유는, 일단 굳이 이 방식을 쓰지 않아도 코드 분석으로 처리해왔기 때문이고 또한 이 방법만으로는 압축 해제는 에뮬레이션할 수 있어도 재압축은 할 수 없기 때문에(보통 게임 내에는 압축 해제 코드만 있지 압축하는 코드는 당연히 없다) 결국 재압축을 위해서는 압축 알고리즘을 분석해야하기 때문이다.
물론 반드시 재압축을 제대로 구현할 필요는 없고, 가령 LZSS 라고 하면 플래그 비트를 전부 원본 데이터를 그대로 복사하는 비트로 설정하고 원본 데이터를 그대로 넣는 식으로 구현해도 된다. 물론 이렇게 하면 데이터 용량이 원본보다 커지므로, 플랫폼에 따라 리패키징이 필요해질 수 있다. 내 경우 코난에서는 그렇게 압축을 제대로 구현하지 않고 처리했고, 예전에 키티야님이 한국어화하신 환영도시에서 그래픽 추출/수정 툴을 만들어드릴 때는 내가 한국어화하는 게 아니므로 데이터 위치를 조정하거나 하는 작업을 마음대로 할 수 없어서 재압축 코드를 제대로 구현했었다. 그리고 지난 번 마나케미아 한글패치의 경우에도 재압축을 제대로 구현해서 처리했다.
다만 재압축의 경우 편법으로 게임 코드를 패치해서 비압축 데이터를 그대로 읽어서 처리하도록 할 수도 있고, 그러면 이 방법과 합하면 압축 루틴을 분석하지 않고도 한국어화를 할 수 있다. 예를 들어서 위에서 언급한 지난 번 마나케미아 한글패치의 경우, 방금 말한 것과 반대의 케이스이긴 하나 원래 비압축 데이터였던 것을 압축 데이터로 받도록 코드 패치를 했었다. 물론 경우에 따라서는 이렇게 코드 패치를 하는 작업이 오히려 압축 분석보다 더 까다로울 수도 있기 때문에 큰 의미는 없다.
어쨌든 그래서 여기서 소개하는 방법은 어디까지나 “압축 해제는 필요하지만 재압축은 굳이 필요없는 상황” 에 가장 적절하다고 할 수 있다. 물론 이런 경우는 사실 한국어화 작업에서 거의 있을 수 없기 때문에 특수한 경우에만 이용될 수 있다.
여기서 예시로 드는 케이스는, 게임의 텍스트만 추출하려는 경우이다. 이 때는 재압축을 할 필요성이 없기 때문에 이 방법이 귀찮음을 없애주는 아주 유용한 방법이 될 수 있다. 물론 텍스트 추출만 해야 할 필요성 자체가 사실상 거의 없기는 하다.
가령 어떤 세가 새턴 게임이 PS2 로 이식되었다고 가정하고, 이 때 PS2 이식판만 정식 한국어화가 되었다고 할 때 이 한국어 텍스트를 세가 새턴 판에도 적용하고 싶을 때(물론 저작권 문제가 생기니 배포는 할 수 없다) 두 게임이 구조가 전혀 달라서 텍스트를 수동으로 매칭시켜서 적용해야 할 경우, PS2 이식판에서는 텍스트를 추출만 하면 되므로 재압축을 할 필요가 없다. 따라서 이런 경우에 본문의 방법을 이용해서 PS2 이식판의 압축 루틴을 분석하지 않고 압축 해제를 할 수 있다.
이 글에서는 위와 같은 상황에 맞아떨어지는, 사쿠라 대전 게임을 예시로 이용해서 설명을 하도록 한다. 이 게임의 PS2 버전은 정식 한국어화로 발매되었는데, 대사 파일이 압축이 되어있다. 이 PS2 버전의 대사 압축을 분석 없이 해제해보도록 한다.
Analysis
일단 이 게임의 내부 파일들은 LAYER0.CVM 이라는 아카이브 파일에 몰려있고, 이는 구글 검색하면 나오는 cvm_tool 과 password 로 풀 수 있기에 과정은 생략한다.
아카이브를 풀면 많은 파일이 나오는데, 그 중에서 주요 대사들이 있는 파일은 .SMX 확장자를 가진 파일들이다. 이 파일들은 대부분 똑같은 구조를 가지고 있는데 그 중 적당히 S0101.SMX 라는 파일의 구조를 보면 아래와 같다.
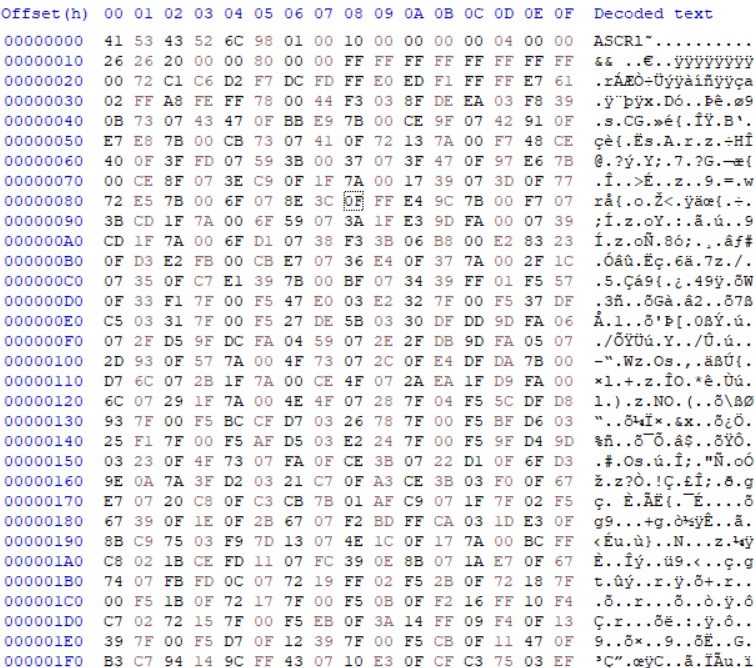
ASCR 이라는 시그니처 문자열과, Size 등의 값들로 추정되는 헤더와 그 뒤에 데이터가 쭉 나열되어 있다. 우선 해야할 일은 디버거를 이용해서 압축 해제 코드의 위치를 찾는 것이다. 딱히 정해진 방법은 없으나 보통 내가 하는 대략적인 과정은 아래와 같다.
-
대사가 나오는 적당한 시점에 메모리를 덤프한다. PS2 게임이라면 PCSX2 에뮬레이터에서 상태 저장을 한 후 p2s 파일(그냥 zip 파일이다) 내에 있는 eeMemory.bin 파일이 메인 메모리 데이터이다.
-
압축 데이터 또는 해제된 데이터(이는 대사를 검색해서 찾는다. 이 게임은 Shift-JIS 를 사용하므로 고유코드 분석도 필요없다)의 위치를 찾는다.
-
게임을 재시작해서 해당 데이터 주소에 r/w bp 를 걸어가면서 추적한다.
-
추적하면서 각 함수의 시작 시점의 인자(빈 공간 주소라든지)를 보고 함수 실행 후에 압축 해제된 데이터가 쓰여지는 등의 동작을 추적한다.
게임에 따라 차이는 있지만 이 작업은 별로 오래 걸리지 않으므로 압축 해제 함수는 쉽게 찾을 수 있다.
이 게임의 경우 압축 해제 함수의 주소는 0x21FE10 이다. IDA 에서 확인해보면 대략 아래와 같다.
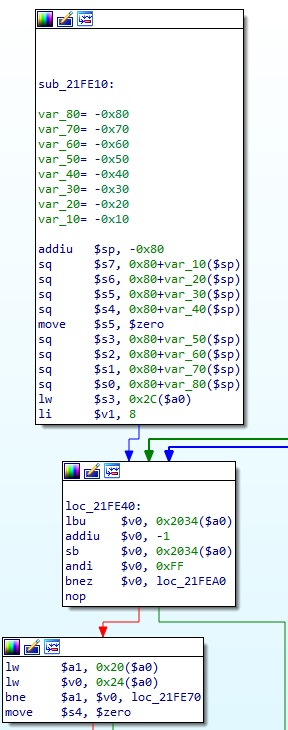
이제 이 함수의 코드를 분석하지 않고, 그대로 에뮬레이션해서 압축을 해제해보자.
Emulation
먼저 콘솔 게임의 에뮬레이션을 간편하게 하기 위해서는 몇 가지 조건이 필요하다. 이게 에뮬레이션을 불가능으로 만드는 것은 아니지만, 여러모로 귀찮아지게 된다.
- 함수가 최대한 Side-effect 가 없는 순수 함수에 가까울수록 좋다.
(내부적으로 인자 외에 별도의 전역 데이터를 사용하는 경우, 이 데이터도 분석해서 에뮬레이션해줘야 하는 등 추가적인 작업이 필요해진다.) - 내부에서 함수 호출이 적으면 적을수록 좋다.
(호출하는 함수도 모두 Side-effect 가 없는 함수라면 그나마 낫기는 하다) - 커스텀 명령어 사용이 적으면 적을수록 좋다.
(만약 이러한 커스텀 명령이 알고리즘상 무시할 수 없는 명령일 경우 따로 구현해줘야 하는 귀찮음이 생긴다)
그나마 다행인 것은, 압축 루틴 구현은 대체로 위 조건을 만족하는 경우가 많다. 굳이 압축 해제 함수 내에서 시스템 콜을 호출해야 할 일도 별로 없고, 별도의 전역 상태를 가질 일도 딱히 없다. 물론 아닌 경우도 있지만, 어차피 대부분 다 무시하거나 적절히 수정해서 에뮬레이션 할 수 있는 부분들이다.
이 게임에서도 물론 위 조건을 거의 다 만족해서, 압축 해제 함수 내에서 다른 함수 호출도 없으며 별도로 전역 메모리에 액세스하는 것도 없다. 또한 PS2 의 이모션 엔진의 특수한 명령어를 사용하지도 않는다. 다만 일부 무시하거나 수정해야 하는 명령어는 있는데 이는 후술한다. 사실 커스텀 명령어 사용의 경우에는, 정 안되면 해당 기종의 오픈 소스 에뮬레이터의 소스 코드를 가져다가 다듬어서 쓰면 어떤 것이든 문제가 없다. 다만 여기서는 Python 에서 Unicorn Engine을 써서 에뮬레이션 할 것이므로 이 에뮬레이터에서 지원하지 않는 것은 적절히 무시하거나 따로 구현해서 해결한다는 것 뿐이다.
우선, 에뮬레이션을 하기 위해서는 최소한의 분석은 필요한데 이 함수의 인자가 어떤 구조이고 어떻게 쓰이는지는 알아야 한다. 디버거로 해당 함수에 bp 를 걸어보면 당연히 압축 해제는 한 두번 실행되는 게 아닌데, 위에서 메모리를 추적해서 압축 해제 코드를 찾았을 때처럼 편의상 대사 데이터가 인자로 들어왔을 때를 찾아서 확인해보면 아래와 같다.
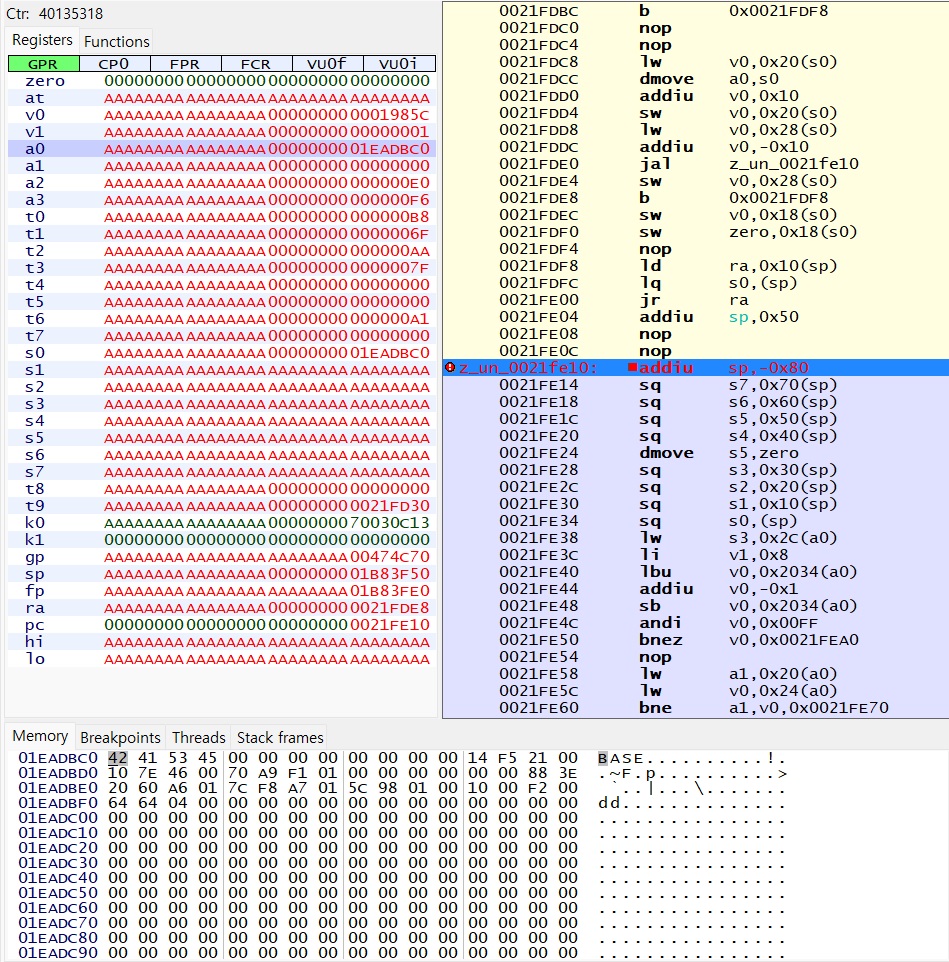
a0 으로 메모리 주소 하나를 인자로 받는데, 아래 메모리 뷰에서 확인해보면 대략 알 수 없는 어떤 구조의 데이터가 들어있다. 대부분 주소 데이터로 보이는 것을 알 수 있다. 하나하나 각각 해당 주소에 들어가서 데이터를 확인하다보면, 아래의 0x1A66020 주소에는 이러한 데이터가 위치해있다.
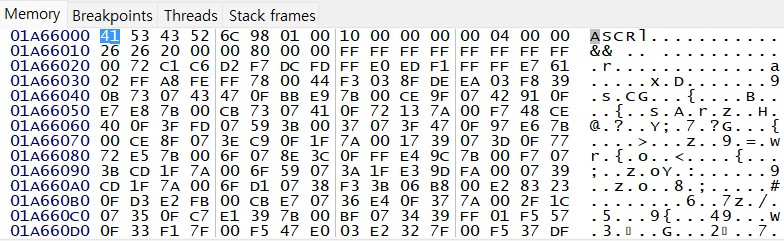
위에서 확인한 압축된 대사 파일인 S0101.SMX 의 +0x20 부분을 가리키는 주소라는 것을 알 수 있다. 이는 헤더로 추정되는 위의 0x20 데이터의 바로 다음 부분이므로 아마도 이 부분부터 실제 압축 데이터라는 것을 추정할 수 있다.
그리고 그 다음에 위치한 0x1A7F87C 주소로 가보면 아래와 같다.
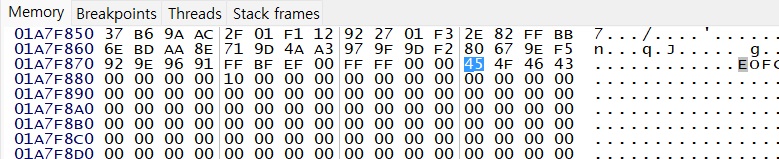
이는 위의 S0101.SMX 파일의 가장 끝 부분에 위치한 데이터이다. 압축 데이터들은 끝에 공통적으로 저렇게 EOFC 등의 문자열을 비롯한 0x10 정도 크기의 데이터를 가지고 있는데, 이 끝을 가리키는 주소이다. 그리고 그 외에 빈 공간으로 보이는 주소도 있는데, 이는 디버거로 진행시켜보면 압축을 해제한 데이터를 쓰는 곳임을 알 수 있다.
그리고 그 뒤에 0x1985C 나 0x46464 같은 데이터도 있는데, 이는 주소는 아니므로 어떤 Size 값으로 추정해볼 수 있다. 이는 실제로 디버거에서 함수를 실행시켜서 압축 해제한 데이터와 대조해서 확인해 보면 맞다는 것을 알 수 있다.
그 외에도 다른 주소들도 있지만, 이 함수 코드를 쭉 살펴보면 그 외에는 아예 사용하지 않는다. 따라서 이는 굳이 에뮬레이션해줄 필요가 없다. 다만, 인자로 받은 주소의 +0x2034 위치의 값을 사용하는데 이는 디버거에서 확인해보면 그냥 1 이 들어있다. 어떤 값인지는 몰라도 대충 에뮬레이션 할 때 1 을 넣어주고 확인해보면 될 것이다.
대략 여기까지만 분석하면 된다. 딱히 분석할 것도 없고 아주 간단하게 끝났다. 이제 이 내용을 바탕으로 그대로 구현해본다.
Implementation
여기서는 에뮬레이터로 간단히 Unicorn Engine 을 사용할 것이다. 위 분석 내용을 바탕으로 구현을 해보면, 별로 딱히 길게 구현할 것도 없고 단순 에뮬레이션이므로 코드는 굉장히 짧게 금방 만들 수 있다. 이 게임의 바이너리는 SLKA_350.03 라는 파일이고, 물론 PS2 게임이므로 그냥 ELF 파일이다. 우선 특별히 예외 처리 없이 그냥 작성해보면 아래와 같다.
import struct
from unicorn import *
from unicorn.mips_const import *
from unicorn.unicorn_const import *
p32 = lambda x: struct.pack("<I", x)
u32 = lambda x: struct.unpack("<I", x)[0]
def decompress(data):
base = 0x11FE80
binary = open("SLKA_350.03", "rb").read()
dec_func = binary[0x21FE10-base:0x220334-base]
mu = Uc(UC_ARCH_MIPS, UC_MODE_MIPS32)
mu.reg_write(UC_MIPS_REG_SP, 0x2008000)
mu.reg_write(UC_MIPS_REG_A0, 0x3000000)
mu.mem_map(0x3000000, 0x100000)
mu.mem_map(0x4000000, 0x1000000)
mu.mem_map(0x5000000, 0x1000000)
mu.mem_map(0x2000000, 0x10000)
mu.mem_map(0x21F000, 0x2000)
mu.mem_write(0x21FE10, dec_func)
mu.mem_write(0x4000000, data)
mu.mem_write(0x3000020, p32(0x4000020) + p32(0x4000000+len(data)-0x10) + p32(u32(data[4:8])-0x10) + p32(0x5000000))
mu.mem_write(0x3000000+0x2034, b"\x01\x00")
mu.emu_start(0x21FE10, 0x220310)
decompressed = mu.mem_read(0x5000000, mu.reg_read(UC_MIPS_REG_S5))
return decompressed
decompress(open("S0101.SMX", "rb").read())
실행해보면 아래와 같은 오류를 얻을 수 있다.
unicorn.unicorn.UcError: Unhandled CPU exception (UC_ERR_EXCEPTION)
원인을 추적해보면, 일단 압축 해제 함수의 시작 부분 코드를 다시 확인해보자.
보통의 32bit MIPS 에서는 메모리 Load/Store 에 sw 와 lw 명령이 쓰이는데, PS2 의 이모션 엔진은 64bit MIPS 기반이고 각 레지스터는 128bit 의 길이를 가진다. 다만 그게 실제로 이런 평범한 코드에서 쓰이는 건 아니고, 벡터 연산을 할때나 쓰인다. 대부분의 분석할 코드는 그냥 32bit 명령이라고 간주해도 무방하다.
그렇지만 여기서는 어쩄거나 함수 프롤로그/에필로그에 sq/lq 를 사용해서 레지스터를 저장하고 복구하고 있다. 간혹 sd/ld 가 쓰이는 경우도 있으나 일단 이 압축 해제 함수에서는 sq/lq 만 쓰인다. 당연히 굳이 함수 프롤로그/에필로그를 에뮬레이션해줘야 할 이유가 전혀 없으므로, 에뮬레이션 시작 주소를 살짝 앞으로 지정해줘서 무시하면 된다.
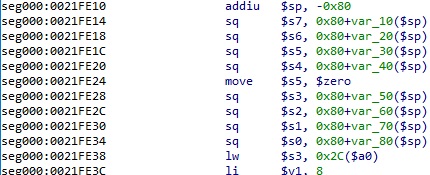
대략 앞의 0x21FE38 부터 시작하는 것으로 하면 충분하다.
그렇게 지정하고 다시 실행해봐도, 또 똑같은 오류가 발생한다. 원인을 추적해보면 이번에는 move 명령 때문이라는 것을 알 수 있다.
위에서 말한 것과 같은 이유로, move 명령 역시 32bit 에서의 move 가 있고 64bit 의 move 가 따로 있다. 위 이미지에서 보다시피 IDA 에서는 그냥 move 로 표시하고 있지만, 사실 PCSX2 디버거에서 보면 dmove 로 표시된다. 물론 이 둘은 opcode 부터 다르다.
여기서는 대부분 32bit 처리이므로, dmove 를 쓸 필요가 없다. 따라서 간단히 dmove 명령을 전부 move 로 바꿔주는 것만으로도 충분하다. 그래서 코드에 살짝 전처리 작업을 추가해보면 아래와 같다.
import struct
from unicorn import *
from unicorn.mips_const import *
p32 = lambda x: struct.pack("<I", x)
u32 = lambda x: struct.unpack("<I", x)[0]
def decompress(data):
base = 0x11FE80
binary = open("SLKA_350.03", "rb").read()
dec_func = bytearray(binary[0x21FE10-base:0x220334-base])
for i in range(0, len(dec_func), 4):
if dec_func[i] == 0x2D:
dec_func[i] = 0x25
dec_func = bytes(dec_func)
mu = Uc(UC_ARCH_MIPS, UC_MODE_MIPS32)
mu.reg_write(UC_MIPS_REG_SP, 0x2008000)
mu.reg_write(UC_MIPS_REG_A0, 0x3000000)
mu.mem_map(0x3000000, 0x100000)
mu.mem_map(0x4000000, 0x1000000)
mu.mem_map(0x5000000, 0x1000000)
mu.mem_map(0x2000000, 0x10000)
mu.mem_map(0x21F000, 0x2000)
mu.mem_write(0x21FE10, dec_func)
mu.mem_write(0x4000000, data)
mu.mem_write(0x3000020, p32(0x4000020) + p32(0x4000000+len(data)-0x10) + p32(u32(data[4:8])-0x10) + p32(0x5000000))
mu.mem_write(0x3000000+0x2034, b"\x01\x00")
mu.emu_start(0x21FE38, 0x220310)
decompressed = mu.mem_read(0x5000000, mu.reg_read(UC_MIPS_REG_S5))
return decompressed
decompress(open("S0101.SMX", "rb").read())
이제 실행해보면 오류 없이 정상적으로 실행되는 것을 볼 수 있다. 그리고 해제된 데이터를 출력해서 확인해보면 정상적으로 압축 해제된 데이터라는 것을 알 수 있다.
Miscellaneous
사실 보면 알겠지만 압축 해제 함수를 알아냈다면 그냥 디버거와 메모리 덤프만으로도 얼마든지 개개의 파일의 압축을 해제할 수 있고, 단지 그걸 Python 으로 별개의 에뮬레이터를 써서 자동화한 것 뿐이다. 물론 디버거만으로 할 경우 디버거에 임의의 큰 데이터를 메모리에 쓰는 기능이 없다면, 압축 함수보다 더 상위 함수를 추적해서 파일명을 받아서 압축 해제된 데이터를 내놓는 함수를 찾고 파일명을 변경해가면서 실행하고 덤프하고 하는 식으로 하게 되는데 이게 여간 귀찮은 작업이 아니기는 하다. 나는 모든 한국어화 작업을 항상 스크립트에서 처음부터 끝까지 모든 작업을 수행하도록 구현하므로 이러한 자동화를 하는 게 좋다.
처음에 위에서 언급한것처럼, 여기에 코드 패치를 살짝만 해주면 재압축 필요없이 비압축 데이터를 받는 것으로 바꿀 수도 있다. 간단히 설명하면, 압축으로 인식하도록 헤더만 적당히 맞춰주고 뒤에는 원본 데이터를 붙인 뒤, 위 압축 해제 함수의 시작 부분을 패치해서 원본 데이터를 그냥 출력 버퍼에 복사하도록 구현하면 끝이다. 물론 이 외에도 경우에 따라 공간 문제나 이것저것 맞춰줘야 할 게 있을 수 있지만 그리 문제되지는 않는다.