CCE 2023 Two steps from Hell's gate 풀이
by

SeHwa
저번 주 주말에 참가한 CCE 2023 CTF 에서 풀었던 Two steps from Hell’s gate 문제에 대한 풀이를 써보기로 한다.
Description
특별히 문제 설명은 없고 주어진 파일은 Alpha.exe 하나뿐이다.
프로그램을 실행하면 아래와 같은 심플한 화면이 보인다.

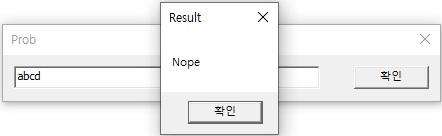
아무 문자열이나 입력해보면 아래처럼 “Nope” 메시지가 출력된다.
그리고 실행되는 프로세스를 확인해보면 자식 프로세스가 생성되어 있는 것을 볼 수 있다.

Analysis
VMO.dll
우선 먼저 Alpha.exe 를 PEview 로 열어서 확인해보면 이상한 section 하나가 있는 것을 볼 수 있다.

PE 파일 하나가 통째로 들어있는 VMP 라는 section 이 보이는데, 이를 추출해서 파일로 만들고 IDA 로 열어보면 아래와 같다.
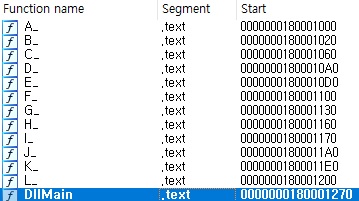
DllMain 이 있는 것으로 보아 dll 파일임을 알 수 있다. 그리고 A_ 부터 L_ 까지의 함수가 있는데, 이는 Export 하는 함수들이다. 실제로 dumpbin /exports VMO.dll 로 확인해보면 아래와 같다.
Dump of file VMO.dll
File Type: DLL
Section contains the following exports for VMO.dll
00000000 characteristics
FFFFFFFF time date stamp
0.00 version
1 ordinal base
12 number of functions
12 number of names
ordinal hint RVA name
1 0 00001000 A_
2 1 00001020 B_
3 2 00001060 C_
4 3 000010A0 D_
5 4 000010D0 E_
6 5 00001100 F_
7 6 00001130 G_
8 7 00001160 H_
9 8 00001170 I_
10 9 000011A0 J_
11 A 000011E0 K_
12 B 00001200 L_
그리고 이 파일 내부에 VMO.dll 이라는 문자열이 있는데, 그래서 이 파일을 VMO.dll 으로 이름을 지었다.
중요한 점으로, Alpha.exe 는 분명 32bit 인데, 이 VMO.dll 은 64bit dll 이다. 즉 아직 이 dll 의 역할이 무엇인지는 몰라도 단순히 LoadLibrary 등으로 로드하는 건 아닐 것이다.
A_ 부터 L_ 까지의 함수 중에서 몇 개를 보면 아래와 같다.
__int64 __fastcall D_(int a1)
{
dword_18001ABE0[BYTE1(a1)] += dword_18001ABE0[BYTE2(a1)];
return 1i64;
}
__int64 __fastcall E_(int a1)
{
dword_18001ABE0[BYTE1(a1)] -= dword_18001ABE0[BYTE2(a1)];
return 1i64;
}
__int64 __fastcall F_(int a1)
{
dword_18001ABE0[BYTE1(a1)] *= dword_18001ABE0[BYTE2(a1)];
return 1i64;
}
__int64 __fastcall G_(int a1)
{
dword_18001ABE0[BYTE1(a1)] &= dword_18001ABE0[BYTE2(a1)];
return 1i64;
}
이는 보기만 해도 레지스터 기반 VM 을 구성하는 명령들임을 추측할 수 있다. 따라서 무엇인지는 몰라도 일단 어딘가에 있는 VM 명령을 해석해야 문제를 풀 수 있을것으로 짐작할 수 있다.
Alpha.exe Child Process
Alpha.exe 를 IDA 로 열어서 WinMain 함수를 보면 아래와 같다.

Mutex 로 부모와 자식 프로세스에서의 실행을 구분하는데, DialogBox 는 자식 프로세스에서 실행된다. 여기서는 우선 자식 프로세스의 동작을 보도록 하자. DialogFunc 프로시저를 확인해보면 아래와 같다.
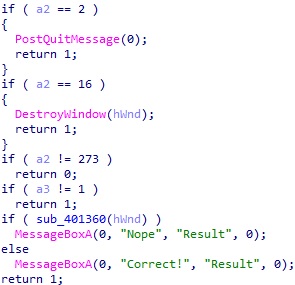
매우 심플한데, 사용자가 확인 버튼을 누르면 sub_401360 이 실행되고 이 리턴값에 따라서 Nope 또는 Correct! 메시지를 출력한다. 리턴값이 0 이어야 Correct! 이고, 아니면 Nope 를 출력한다. 이 함수 코드를 보면 아래와 같다.
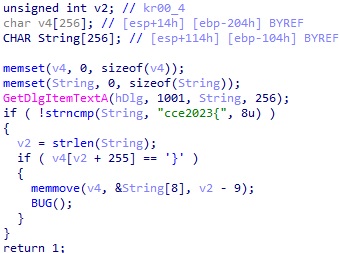
사용자가 입력한 값의 앞 부분이 "cce2023{" 인지 체크하고, 끝 부분이 "}" 인지 체크해서 맞으면 임시 버퍼에 그 사이의 문자열을 복사한 다음 BUG() 라고 출력되는데, 여기서부터는 어셈블리를 봐야 한다.

ud2 명령과 이후 알 수 없는 데이터가 나오는 구조가 반복되는 것을 볼 수 있다. ud2 명령은 예외를 발생시키므로 이후 정상적으로는 진행되지 않는다. 그리고 이러한 구조가 어느 정도 반복되고 마지막 부분에 epilogue 코드가 있다.

두 가지 플로우가 보이는데, 직전의 eax 값을 그대로 리턴하거나 또는 1 을 리턴하는 것을 볼 수 있다. 위에서 봤다시피 Correct! 메시지가 뜨기 위해서는 0 을 리턴해야 한다. 따라서 eax 가 0 으로 설정된 상태로 여기에 도달해야 문제를 푼 것으로 짐작할 수 있다.
자식 프로세스는 별 다른 특이점이 없고 위의 내용이 전부이다. ud2 명령과 알 수 없는 데이터가 무엇인지만 알면 될 것이다.
Alpha.exe Parent Process
부모 프로세스에서는 먼저 일종의 초기화 함수인 sub_402240 을 실행하고, 그 다음 자식 프로세스 생성을 하는데 dwCreationFlags 에 DEBUG_PROCESS 를 설정하고 생성하므로 바로 자식 프로세스를 디버그하는 상태가 된다.
그리고 핵심인 sub_401000 함수를 실행하는데, 앞 부분을 일부 보면 아래와 같다.
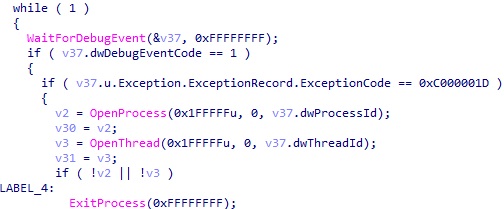
자식 프로세스에 대해 Debug Event 를 계속 모니터링하는데, dwDebugEventCode 에 대해서는 MSDN에서 확인할 수 있다시피 1 은 EXCEPTION_DEBUG_EVENT 이다. 즉 자식 프로세스에서 예외가 발생하고, ExceptionCode 가 0xC000001D 인 경우를 체크해서 맞을 때만 처리를 하고 이외에는 무시한다. (단 자식 프로세스가 종료되는 것만 체크해서 부모 프로세스도 종료한다.)
이는 위에서 자식 프로세스 분석을 했을 때 봤던 ud2 명령이 발생할 때를 모니터링하는 것이다. ud2 명령이 실행되려고 하면 이 조건문이 맞아서 특정한 처리를 하기 위한 루틴을 실행하게 된다.

예외가 발생했다면 먼저 위의 루틴을 실행하는데, ReadProcessMemory 로 자식 프로세스의 eip + 2 위치에서 8bytes 를 읽는다. 이는 위에서 말했듯이 ud2 명령이 실행되면 오는 곳이므로 eip 도 ud2 명령이 있는 주소이다. ud2 명령은 2bytes 이므로 결국 ud2 명령 뒤에 있는 8bytes 를 읽는 것이다.
읽은 8bytes 값이 1일 때만 위의 루틴을 실행하는데, 다시 위의 ud2 명령이 있는 부분을 헥스 에디터로 확인해보면 아래와 같다.
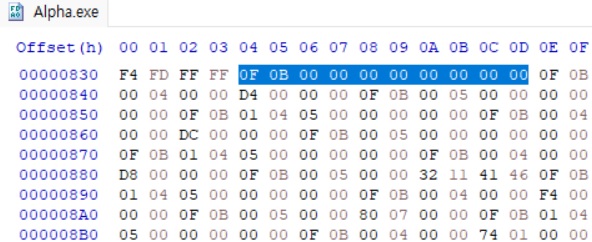
ud2 명령은 0F 0B 이고, 구조를 보면 ud2 명령 뒤에는 8bytes 값이 오고 다시 ud2 명령이 오는 식으로 구조가 반복되는 것을 볼 수 있다. 그리고 이를 마지막까지 확인해보면 알겠지만 이 8bytes 값이 0 인 경우는 위에서 강조된 첫 번째 부분밖에 없다. 따라서 위의 조건문에서 0 인지 체크하는 것은 일종의 시작 단계에서의 별도의 처리를 하기 위한 것임을 생각할 수 있다.
그러면 먼저 8bytes 값이 0 인 경우에 실행하는 루틴을 먼저 확인해보자.

몇 가지 주석과 명명을 해놨었는데, VMO_dll 은 VMP section 에 있던 VMO.dll 파일의 데이터를 메모리에 로드하고 그 시작 주소를 가리키는 변수이다. PE 파일 구조대로 몇 가지를 읽는데, 우선 EXPORT table 을 읽고 마지막 항목의 주소를 가져온다. 위에서 아까 VMO.dll 파일의 EXPORT table 을 보면 A_ 부터 L_ 까지의 함수가 있고, 가장 마지막 함수는 L_ 이었다. 따라서 먼저 L_ 함수의 주소를 가져오는 것이다.
그리고 여러가지 함수가 있는데, 이는 사실 대부분 VMO.dll 의 입장에서 함수를 호출하기 위한 일종의 Wrapper 들이다. 그 모든 것에 핵심이 되는 함수가 VMO_call 로 명명한 함수인데, 이는 중요하므로 나중에 별도로 후술한다.
복잡해보이지만 대부분 자세히 볼 필요는 없다. 다음으로 8bytes 가 0 인 경우의 루틴을 확인해보자.

아까의 루틴은 처음 한 번만 실행되고, 사실상 이 루틴이 계속 실행되는 반복 루틴이다. 기본적으로 별반 다르지는 않으나 좀 더 심플하다. 그리고 마지막에 eax 를 설정하는 부분이 의미심장하게 보인다. 아까 말했다시피 자식 프로세스에서 eax 가 0 으로 리턴되어야 Correct! 가 출력되는데, 여기서 eax 가 0 으로 설정되도록 하는 것이 목표가 될 것임을 짐작할 수 있다.
이 값은 VMO_call 의 리턴값과 관련되어 있고, 이 루틴도 실질적으로는 VMO_call 을 계속 호출하는 것에 불과하다. 따라서 이게 무엇인지 알아보아야 할 것이다.
Heaven’s Gate
이 함수의 내용을 중간은 적당히 생략하고 보면 아래와 같다.
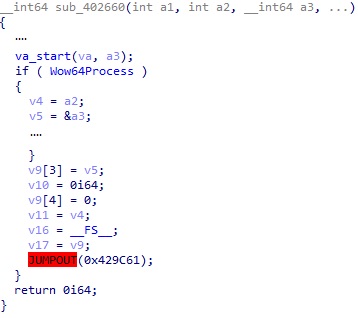
무언가 Hex-rays 에서는 제대로 분석이 안 되는 것을 볼 수 있다. 마지막의 이상하게 보이는 부분을 어셈블리로 확인해보자.
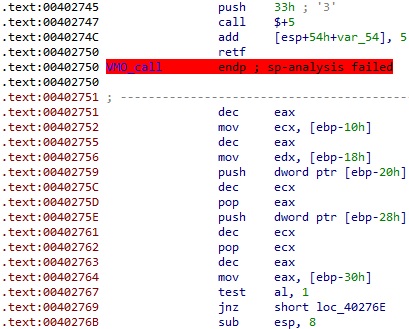
call $+5 나 retf 등의 명령이 보인다. 이 형태는 이전에 CTF 나 여기저기에서 자주 봤던 일명 Heaven’s gate 이다. 즉 retf 뒤에 있는 명령들은 x64 명령들이다. dec eax(0x48) 가 계속 나오는 것만 봐도 바로 짐작할 수 있다.
retf 가 실행되면 현재 실행 컨텍스트가 64bit 로 전환되어 바로 뒤의 명령을 실행하기 시작한다. 여기부터는 64bit 로 분석을 해야 한다. 이 부분은 별로 길지도 않으므로 적당히 저 부분만 떼서 IDA 로 보자.
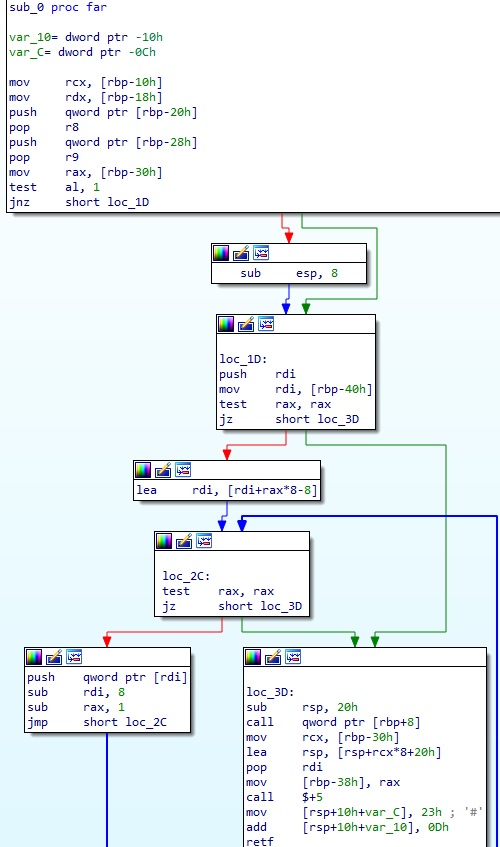
당시에는 디버거 분석은 어떻게 해야할지 당장 떠오르지 않아서 일단 정적 분석만 진행했다. 사실 이 시점에서는 이미 어떤 동작인지 예상이 가능하므로 대강 훑어보기만 했다. 결과적으로 이는 어떤 함수를 호출하고 나서 다시 32bit 로 변경하는 것인데, 다른 코드는 대부분 인자 설정 등 잡다한 작업들이다. 어떤 함수를 호출하는지는 VMO_call 함수를 호출할 때의 인자를 디버거로 확인하면 짐작이 가능하다.
간단하게 예를 하나 들어보자. 아까 ud2 명령 뒤의 8bytes 가 0일 때 호출되는 VMO_call 는 L_ 함수의 주소를 인자로 주는 것 같다고 서술했었다. 해당 VMO_call 호출시의 인자를 디버거에서 확인해보면 아래와 같다.
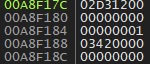
VMO_call 함수는 3개의 인자와 그 이후로는 가변 인자를 받는데, 3번째 인자가 이후 받는 인자의 개수이다. 여기서는 1 이므로 하나의 인자를 더 받는 것이다. 그러나 이 함수는 3번째 인자를 제외하고는 모두 64bit 인자들을 받기 때문에, 사실 첫 번째와 두 번째 인자는 둘을 하나로 이어서 64bit 값 하나를 이루는 것이고 뒤의 인자도 마찬가지이다.
위 예시에서 보면 실제로 첫 번째 인자는 0x0000000002D31200 을 받은 것으로 생각할 수 있고, 1 뒤의 인자는 0x0000000003420000 을 받은 것이다.
첫 번째 인자가 L_ 의 주소로 추정되는 것이었는데, 해당 주소로 가서 직접 확인해보면 아래와 같다.
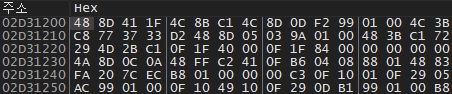
x64 명령으로 보이는 데이터가 있는 것을 볼 수 있다. 이 영역은 아까 VMO_dll 영역이기 때문에, 실제로 VMO.dll 을 IDA 로 열어서 0x1200 offset 에 있는 것을 확인해보면 다음과 같다.
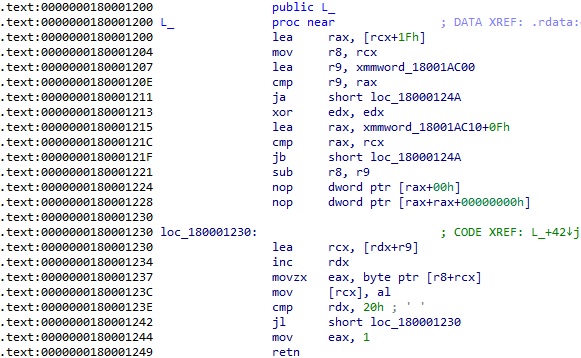
즉 결과적으로 VMO_call 은 첫 번째 인자로 받은 주소에 있는 코드를 실행하고, 이 때 이 코드를 실행할 때의 인자도 전달하는 것으로 생각할 수 있다. 실제로는 이 루틴에서 호출되는 VMO_call 함수는 모두 VMO.dll 의 A_ 부터 L_ 까지의 함수를 실행하는 역할을 한다. (물론 더 안쪽을 분석해보면 메모리 할당 등 다른 용도로도 많이 호출된다.)
Solving
분석할 부분은 다 분석했으나, 마지막으로 아까의 VMO_call 반복 루틴에서 마지막 부분을 보자.

VMO_call 로 A_ 부터 L_ 까지의 어떤 함수를 호출한 다음 리턴값에 대해 10 을 곱한 값을 eip 에 더하는 것을 볼 수 있다. 이는 위에서 봤듯이 ud2 명령 2bytes 와 뒤의 8bytes 를 합해서 한 명령 당 10bytes 이므로 이렇게 하는 것이다. 그리고 여기서 짐작할 수 있는 것은, VM 문제인 만큼 당연히 루프 등을 구현하기 위해 실행 흐름 변경이 필요하고 여기서 VMO_call 의 리턴값이 그 역할을 할 것이라 생각할 수 있다. 만약 -1 을 리턴한다면 이전의 명령으로 돌아가서 실행하는 것이 된다.
Parsing VM Instructions
이제 VM 명령을 파싱해서 해석해야 한다. 다행히 VM 구조는 복잡하지 않고 매우 심플하므로 거의 분석할 필요도 없이 바로 변환할 수 있다. 이런 류의 문제를 풀 때 내가 즐겨쓰는 방식으로, x86 명령으로 변환해서 IDA 로 플로우를 보는 것이 있다. 이를 위해서 각 VM 명령들을 대응되는 x86 명령으로 변환해야 한다. L_ 은 처음 한 번 실행되는 초기화 작업이므로 무시하고 A_ 부터 K_ 까지만 변환하도록 한다. 간단하게 Python 으로 변환 스크립트를 구현했다.
import struct
import sys
us32 = lambda x: struct.unpack("<i", x)[0]
u32 = lambda x: struct.unpack("<I", x)[0]
u64 = lambda x: struct.unpack("<Q", x)[0]
vm = open("vmcode", "rb").read()
rs = ["eax", "ebx", "ecx", "edx", "esi", "edi", "ebp"]
rs2 = ["al", "bl", "cl", "dl"]
cnt = 0
idx = 0
while True:
if idx >= len(vm): break
if u64(vm[idx+2:idx+10]) == 0:
idx += 10
continue
op = vm[idx+2]
r = vm[idx+3]
r2 = vm[idx+4]
r3 = vm[idx+5]
v = u32(vm[idx+6:idx+10])
sv = us32(vm[idx+6:idx+10])
print("label" + str(cnt) + ": ")
if op == 0:
print("mov " + rs[r] + ", " + hex(v))
elif op == 1:
print("mov dword ptr [0x5000+" + rs[r] + "], " + rs[r2])
elif op == 2:
print("mov " + rs[r] + ", dword ptr [0x5000+" + rs[r2] + "]")
elif op == 3:
print("add " + rs[r] + ", " + rs[r2])
elif op == 4:
print("sub " + rs[r] + ", " + rs[r2])
elif op == 5:
print("mul " + rs[r2])
elif op == 6:
print("and " + rs[r] + ", " + rs[r2])
elif op == 7:
print("jmp label" + str(cnt+sv))
elif op == 8:
print("cmp " + rs[r] + ", 1")
print("jnz label" + str(cnt+sv))
elif op == 9:
print("cmp " + rs[r2] + ", " + rs[r3])
print("xor " + rs[r] + ", " + rs[r])
print("setne " + rs2[r])
elif op == 10:
print("call " + rs[r])
idx += 10
cnt += 1
ud2 명령의 시작부터 마지막까지의 데이터를 vmcode 라는 파일로 미리 추출해놓았다. 메모리는 편의상 적당히 0x5000 을 기준으로 잡았고, K_ 의 경우(op = 10) 마지막 한 번만 호출되므로 그냥 아무 적당한 명령으로 call 로 설정해놓았다.
이렇게 하고 실행하면 아래와 같은 식으로 변환이 된다.
label0:
mov esi, 0xd4
label1:
mov edi, 0x0
label2:
mov dword ptr [0x5000+esi], edi
label3:
mov esi, 0xdc
label4:
mov edi, 0x0
label5:
mov dword ptr [0x5000+esi], edi
label6:
mov esi, 0xd8
label7:
mov edi, 0x46411132
...
label300:
mov ecx, dword ptr [0x5000+esi]
label301:
cmp ecx, ebx
xor ebx, ebx
setne bl
label302:
cmp ebx, 1
jnz label205
label303:
mov esi, 0xdc
label304:
mov eax, dword ptr [0x5000+esi]
label305:
call eax
이제 이 내용을 텍스트 파일로 출력하고 그대로 적당히 어셈블해서 바이너리로 만들 수 있다.
from keystone import *
code = open("code.asm", "rb").read()
ks = Ks(KS_ARCH_X86, KS_MODE_32)
encoding, count = ks.asm(code)
out = b''.join(map(lambda x: x.to_bytes(1, byteorder="little"), encoding))
open("out", "wb").write(out)
Analyzing VM code
이제 이 바이너리를 IDA 로 열어보면 아래와 같다.
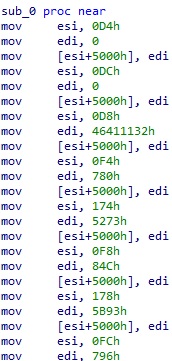
위와 같은 수상한 테이블 초기화 코드가 쭉 이어지고, 그 뒤에 아래와 같은 플로우가 보인다.
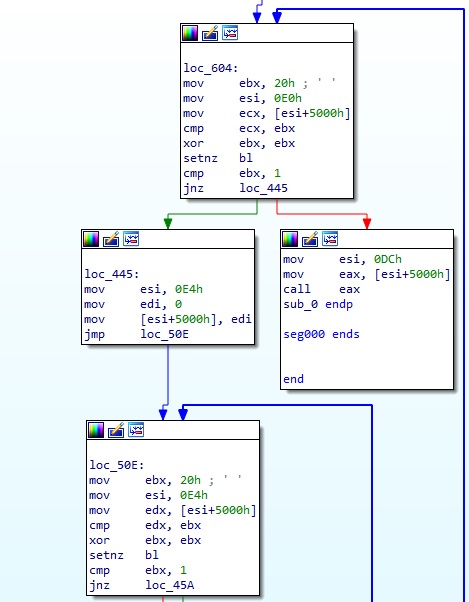
원래는 Hex-rays 때문에 이런 변환을 하는 것인데, 대응되는 명령이 적절하지 않아서 그런지 Hex-rays 가 C 코드로 제대로 변환을 하지 못했다. 그래서 그냥 어셈블리를 보고 분석했다. 결과적으로는 일단 사용자가 입력한 정답 문자열(cce2023{} 을 제외한 안쪽 문자열)을 L_ 함수에서 VM 메모리에 미리 쓴 다음 해당 문자열에 여러가지 연산을 해서 결과를 받는 것이다.
일단 이 코드를 분석하면서 적당히 pseudo code 로 만들어보면 아래와 같다.
d8 = 0x46411132
dc = 0
for( int i = 0; i < 32; i++ ){
for( int j = 0; j < 32; j++ ){
d8 = (0xdeece66d * d8 + 11) & 0x7fffffff
dc += (d8 & 0xFFFF) * (flag[j] & 0xff)
}
for( int j = 0; j == table_f4[i*4]; j++ )
dc -= 0x8000
dc -= table_174[i*4]
}
if( dc == 0 ) Correct!
이렇게 만들어놓으면 대충 윤곽이 잡힌다. 값 초기화 루틴에서 대략 두 가지 table 을 만드는 것으로 보인다. 이를 이용해서 flag 를 역산하면 문제를 푸는 것이 된다.
Z3 Solver
일단 이를 z3 로 풀어보기 위해 처음에 만들었던 코드는 아래와 같다.
from z3 import *
import struct
u32 = lambda x: struct.unpack("<I", x)[0]
tbl1 = []
tbl2 = []
t = open("table", "rb").read()
for i in range(0, len(t), 4):
if i < len(t)//2:
tbl1.append(u32(t[i:i+4]))
else:
tbl2.append(u32(t[i:i+4]))
s = Solver()
flag = [ BitVec("flag%i"%i, 8) for i in range(32) ]
var = 0
seed = 0x46411132
for i in range(32):
for j in range(32):
seed = (0xdeece66d * seed + 11) & 0x7FFFFFFF
var += (seed & 0xFFFF) * flag[j]
for j in range(tbl1[i]):
var -= 0x8000
var -= tbl2[i]
s.add(var == 0)
for i in range(32):
s.add(flag[i] >= 32)
s.add(flag[i] <= 127)
print(s.check())
result = ""
for i in range(32):
result += chr(int(str(s.model()[flag[i]])))
print("cce2023{" + result + "}")
그러나 제대로 된 결과가 전혀 나오지 않았다. 정확히는 무수히 많은 정답이 나왔다. 그리고 다시 생각해보니 z3 의 특성상 BitVec 으로 할 경우 위와 같은 연산에서는 음수 문제로 인해 결과가 제대로 나오지 않을 수 있을 것 같았다. 그래서 원래 코드만으로는 확신할 수 없는 한 가지 가정을 하기로 했다.
var 는 누적되지 않고, flag 1글자(i 루프)를 처리할때마다 올바른 flag 인 경우 정확히 0 이 될 것이다.
그래서 이 가정을 바탕으로 코드를 조금 수정하면 아래와 같다.
seed = 0x46411132
for i in range(32):
var = 0
for j in range(32):
seed = (0xdeece66d * seed + 11) & 0x7FFFFFFF
var += (seed & 0xFFFF) * flag[j]
s.add(var == (tbl1[i]*0x8000) + tbl2[i])
그러나 이렇게 해도 결과가 제대로 나오지 않았다. 여기서 다시 위 코드를 바탕으로 연산의 구조를 고찰해보았다.
위에서 flag[j] 를 변수로 생각하고, 곱하는 값(seed & 0xFFFF)을 계수로 생각하고 뒤에서 var 과 특정 값을 비교하는 것을 생각해보면 이는 결과적으로 i 루프 하나가 방정식이라고 볼 수 있으며 계수만 다른 방정식이 32개가 있는 연립방정식으로 생각할 수 있다.
즉 flag 를 x 로 생각하면 대략 아래와 같은 연립방정식이 된다.
\[\begin{align} a_0x_0+a_1x_1+...+a_{31}x_{31}=b_0 \\ a_{32}x_0+a_{33}x_1+...+a_{63}x_{31}=b_1 \\ .... \end{align}\]32개의 변수에 대한 식이 32개가 있으므로 이 방정식을 푸는 것은 전혀 문제가 없어보인다. 그래서 이를 풀기위해 Mathematica 에 넣으려고 식을 만들던 도중에, 그냥 z3 에서 BitVec 이 아닌 Int 로 바꾸면 정수 방정식으로 취급하는 풀이가 되지 않을까 하는 생각에 아래와 같이 바꿔서 실행해보았다.
from z3 import *
import struct
u32 = lambda x: struct.unpack("<I", x)[0]
tbl1 = []
tbl2 = []
t = open("table", "rb").read()
for i in range(0, len(t), 4):
if i < len(t)//2:
tbl1.append(u32(t[i:i+4]))
else:
tbl2.append(u32(t[i:i+4]))
s = Solver()
flag = [ Int("flag%i"%i) for i in range(32) ]
seed = 0x46411132
for i in range(32):
var = 0
for j in range(32):
seed = (0xdeece66d * seed + 11) & 0x7FFFFFFF
var += (seed & 0xFFFF) * flag[j]
s.add(var == (tbl1[i]*0x8000) + tbl2[i])
for i in range(32):
s.add(flag[i] >= 32)
s.add(flag[i] <= 127)
print(s.check())
result = ""
for i in range(32):
result += chr(int(str(s.model()[flag[i]])))
print("cce2023{" + result + "}")
실행하니 아래와 같이 바로 플래그를 얻을 수 있었다.
sat
cce2023{2757b093fe695771169054898e3e81e7}
Bonus
32개 변수와 32개의 식을 가진 연립일차방정식이라는 것은 즉 유일해가 존재한다면 역행렬을 구하는 것으로도 아주 쉽게 해를 구할 수 있다는 뜻이다. 그래서 SageMath를 사용해서 역행렬을 구하고 풀어보면 동일하게 플래그를 얻을 수 있다.
import struct
u32 = lambda x: struct.unpack("<I", x)[0]
tbl1 = []
tbl2 = []
t = open("table", "rb").read()
for i in range(0, len(t), 4):
if i < len(t)//2:
tbl1.append(u32(t[i:i+4]))
else:
tbl2.append(u32(t[i:i+4]))
mat = []
vec = []
seed = 0x46411132
for i in range(32):
for j in range(32):
seed = (0xdeece66d * seed + 11) & 0x7FFFFFFF
mat.append(seed & 0xFFFF)
vec.append((tbl1[i]*0x8000) + tbl2[i])
A = matrix(32, 32, mat)
V = vector(vec)
FLAG = A.inverse() * V
result = ""
for i in range(32):
result += chr(FLAG[i])
print("cce2023{" + result + "}")